TensorRT------性能优化
1 开启融合
1.1 Layer融合
TensorRT试图在构建阶段在网络中执行许多不同类型的优化。在第一阶段,尽可能将各层融合。融合将网络转化为更简单的形式,但保持了相同的整体行为。在内部,许多层实现具有在创建网络时无法直接访问的额外参数和选项。相反,融合优化步骤检测支持的操作模式,并使用内部选项集将多个层融合到一个层中。
考虑卷积后是ReLU激活的常见情况。使用这些操作创建网络涉及使用addConvolutionNd添加卷积层,然后使用激活类型为kRELU的addActivation添加激活层。未优化的图将包含分别用于卷积和激活的单独层。卷积的内部实现支持直接从卷积内核一步计算输出上的ReLU函数,而不需要第二次内核调用。融合优化步骤将检测卷积,然后检测ReLU。验证实现是否支持这些操作,然后将它们融合到一个层中。
为了查看发生了哪些融合,构建器将其操作记录到构建过程中提供的记录器对象中。优化步骤在kINFO日志级别。要查看这些消息,请确保将它们记录在ILogger回调中。
通常通过创建一个新图层来处理融合,该图层的名称包含融合的两个图层的名称。例如,名为ip1的MatrixMultiply层(InnerProduct)与名为relu1的ReLU激活层融合,以创建名为ip1+relu1
1.2 融合的类型
以下列表描述了支持的融合类型:
支持的图层融合
ReLU激活:单个激活层将取代执行ReLU的激活层,然后是执行ReLU。
卷积和ReLU激活:卷积层可以是任何类型,值不受限制。激活层必须是ReLU类型。
卷积和GELU激活:输入和输出精度应该相同,都是FP16或INT8。激活层必须是GELU类型。TensorRT应该在NVIDIA Turing或更高版本的CUDA 10.0上运行。
卷积和CLIP激活:卷积层可以是任何类型,值不受限制。激活层必须是CLIP类型。
缩放和激活:缩放层和激活层可以融合成一个激活层
卷积和ElementWise操作:可以将卷积层与ElementWise层中的简单sum,min,max融合到卷积层中。除非广播跨越batch size,否则sum不得使用广播
填充和卷积/反卷积:如果所有填充大小都是非负的,则填充后的卷积或反卷积可以融合到一个卷积/反卷积层中。
Shuffle和Reduce:无需重新整形的Shuffle层,然后是Reduce层,可以融合到一个Reduce图层中。Shuffle层可以执行排列,但不能执行任何重塑操作。Reduce层必须具有keepDimensions维度集。
Shuffle和Shuffle:每个Shuffle层由一个转置、一个整形和第二个转置组成。一个Shuffle层和另一个Shuffle层可以被单个Shuffle(或什么都没有)替换。如果两个Shuffle层都执行重塑操作,则只有当第一个Shuffle的第二个转置与第二个shuffles的第一个转置相反时,才允许进行这种融合
scale:可以擦除将0相加、乘以1或计算1的幂的缩放层
卷积和缩放:调整卷积权重可以将卷积层与kUNIFORM或kCHANNEL的缩放层合并为一个卷积。如果scale具有非常量的power参数,则禁用此融合。
卷积和通用激活:这种融合发生在下面提到的逐点融合之后。具有一个输入和输出的逐点激活层可以称为通用激活层。卷积层和通用激活层可以融合成一个卷积层。
Reduce:它执行平均池化,池化层将替换它。在使用kAVG操作进行批处理之前,Reduce层必须设置keepDimensions,并在CHW输入格式的H和W维度上进行缩减。
卷积和池化:卷积层和池化层必须具有相同的精度。卷积层可能已经具有来自先前融合的融合激活操作。
深度可分离卷积:带有激活的深度卷积,然后是带有激活的卷积,有时可以融合到一个优化的DepSepConvolution层中。两个卷积的精度必须为INT8,设备的计算能力必须为7.2或更高。
Softmax和Log:如果它尚未与之前的Log操作融合,则可以将其融合到单个Softmax层中。
Softmax和TopK:它可以融合成单层。Softmax可能包含也可能不包含Log操作。
支持Reduce操作融合
GELU:表示以下方程的一组Unary和ElementWise层可以融合到单个GELU scale操作中
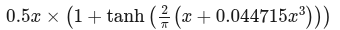
或者另一种表示方式:
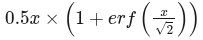
L1Norm:一个Unary层kABS操作和一个Reduce层kSUM操作可以合并为一个L1Norm缩减操作。
平方和:具有相同输入(平方运算)的ElementWise层,然后进行kSUM缩减,可以合并为一个平方和缩减运算。
L2Norm:平方和运算后的kSQRT UnaryOperation可以合并为单个L2Norm缩减运算。
LogSum:一个Reduce层kSUM和一个kLOG UnaryOperation可以合并为一个LogSum缩减操作
LogSumExp:一个Unary kEXP ElementWise操作,然后是一个LogSum融合,可以融合成一个LogSummex缩减操作
pointwise融合
多个相邻的逐点层可以融合到一个逐点层中,以提高性能。
支持以下类型的逐点图层,但有一些限制:
激活:支持所有ActivationType。
常量:只有一个值的常量(大小==1)。
ElementWise:支持所有ElementWise操作。
Pointwise:Pointwise本身也是一个Pointwise层。
缩放:仅支持缩放模式:kUNIFORM。
Unary:支持所有Unary操作。
融合的逐点层的大小不是无限的,因此某些层可能无法融合。
Fusion创建了一个新层,其名称由两个融合层组成。例如,名为add1的ElementWise层与名为relu1的ReLU激活层融合,创建了一个名为fusedPointwiseNode(add1,relu1)的新层。
Q/DQ 融合
有关优化包含QuantizeLinear和DequantizeLinear层的INT8和FP8网络的建议,请参阅显式量化部分
Multi-Head Attention 融合
TensorRT支持两种不同的方法来触发多头注意力(MHA)融合:
使用IAttention API将注意力操作员添加到网络中,以及
使用IMatrixMultipleLayer和ISoftMaxLayer等原始INetwork层构建注意力
MHA计算softmax(Q*K^T/scale⊗mask)*V,其中:
Q是query嵌入
K是key嵌入
V是value嵌入
mask可以是:
一个布尔掩码,表示Softmax允许相应的位置参加。
添加掩模偏移Q*K^T/scale
Q的形状为[B,N_Q,S_Q,H],K和V的形状为/B,N_kv,S_kv,H]。其中:
B是batch size
N_q和N_kv分别是查询和键/值的关注头数量
S_q和S_kv分别是查询和键/值的序列长度。
H是头部/隐藏尺寸
当N_kv==1和N_q%N_kv==0时,还分别支持组查询注意力(GQA)和多查询注意力(MQA)融合
我们强烈建议根据下表中的上述限制定制您的模型,以便进行MHA融合。它很重要,因为它通过将内存占用从O(S^2)显著减少到O(S)来支持大序列长度,其中S是序列长度。除此之外,它还具有Op融合的性能优势,即减少内存流量、提高硬件利用率、减少内核启动和同步开销
Supported MHA Fusions on SM100, SM110
Supported MHA Fusion for Other SM Versions
方法1(推荐):使用IAttetion API
Attention提供了一个简单干净的API,将注意力集中在网络上,并在TensorRT中触发MHA融合。有关更多详细信息,请参阅IAttention操作文档。
默认情况下,IAttention假设注意力应始终使用融合内核。如果添加的注意力不符合上表中列出的限制,因此无法找到融合的内核,则引擎构建将出错。如果用户希望允许IAttention回退到使用非融合内核,则可以通过函数IAttention::setDecombable将IAttentions设置为可分解
要量化IAttention,必须对所有查询、键和值输入使用遵循显式量化规则的Q/DQ对,并分别使用另一个归一化量化scale和一个通过IAttention::setNormalizationQuantizeScale和IAttention::setNormalizeQuantizeToType提供给IAttentions的数据类型的归一化量化。归一化量化scale和归一化量化到数据类型必须与Q/DQ对的数据类型相匹配。IAttention的输出可以用可选的量化器进行量化
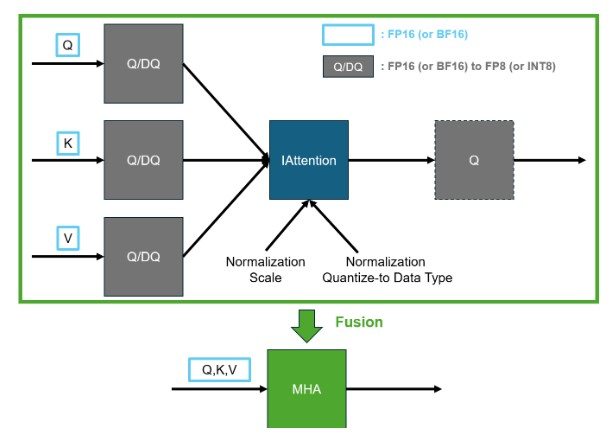
要为IAttention应用因果掩码,用户可以使用函数IAttention::setCausal。要应用任意掩码,用户可以通过函数IAttention::setMask提供布尔掩码或浮点掩码
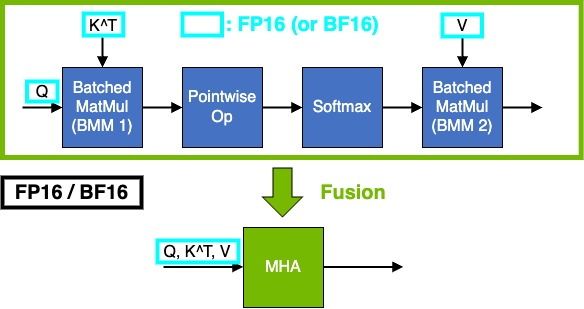
方法2:用原始的“INetwork”层构造注意力
下图展示了如何构建FP16、BF16、FP8和INT8注意点来触发MHA融合。batch MatMul使用IMatrixMultiplyLayer,Softmax使用ISoftMaxLayer,Q/DQ使用IQuantizeLayer和IDequantizeLayer