CUDA性能优化 ---- 通过矢量化内存访问提高性能
许多CUDA内核都是带宽受限的,新硬件中flops与带宽之比的增加导致了更多带宽受限的内核。这使得采取措施缓解代码中的带宽瓶颈变得非常重要。在这篇文章中,我将向您展示如何在CUDA C++中使用向量加载和存储来帮助提高带宽利用率,同时减少执行的指令数量
让我们从以下简单的内存复制内核开始
__global__ void device_copy_scalar_kernel(int* d_in, int* d_out, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
for (int i = idx; i < N; i += blockDim.x * gridDim.x) {
d_out[i] = d_in[i];
}
}
void device_copy_scalar(int* d_in, int* d_out, int N)
{
int threads = 256;
int blocks = min((N + threads-1) / threads, MAX_BLOCKS);
device_copy_scalar_kernel<<<blocks, threads>>>(d_in, d_out, N);
}在这段代码中,我使用了网格步幅循环,这在之前的
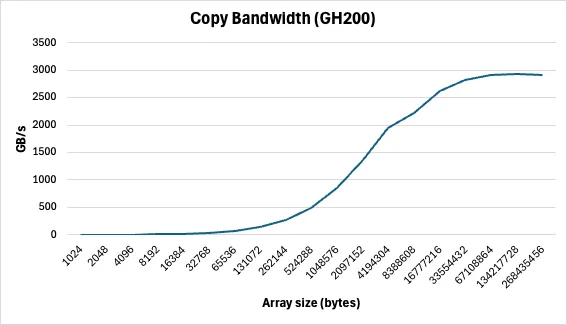
帖子中有所描述。图1显示了作为拷贝大小函数的内核吞吐量(GB/s)。
我们可以使用CUDA工具包附带的cuobjdump工具检查此内核的汇编指令
%> cuobjdump -sass executable标量复制内核主体的SASS包括以下指令
...
LDG.E R3, desc[UR6][R2.64] ;
...
STG.E desc[UR6][R4.64], R3 ;
... LDG.E和STG.E指令分别从全局存储器加载和存储32位。
我们可以通过使用矢量化的加载和存储指令LDG来提高此操作的性能。LDG.E.{64,128}和STG.E.{64,128}。这些操作也加载和存储数据,但以64或128位宽进行。使用矢量化加载可以减少指令总数,降低延迟,并提高带宽利用率.使用矢量化加载的最简单方法是使用CUDA C++标准头文件中定义的矢量数据类型,如int2、int4或float2、float4.这些类型表示打包在一个数据单元中的多个值。您可以通过C++中的类型转换轻松使用这些类型.例如,在C++中,你可以使用reinterpret_cast<int2*>(d_in)将int指针d_in重写为int2指针,该指针将一对“int”值视为一个单元。在C99中,您可以使用强制转换运算符执行相同的操作:(int2*(d_In))
解引用这些指针将导致编译器生成矢量化指令
int2* int2Ptr = reinterpret_cast<int2*>(d_in);
int2 data = int2Ptr[0]; // Loads the first two int values as one int2然而,有一个重要的警告:这些指令需要对齐的数据。设备分配的内存会自动对齐到数据类型大小的倍数,但如果偏移指针,偏移量也必须对齐。例如,reinterpret_cast<int2*>(d_in+1)是无效的,因为d_in+1没有与sizeof(int2)的倍数对齐.
如果使用“对齐”偏移量,则可以安全地偏移数组,如interpret_cast<int2*>(d_in+2).
您还可以使用结构生成矢量化加载,只要该结构的大小是两个字节的幂。
struct Foo {int a, int b, double c}; // 16 bytes in size
Foo *x, *y;
…
x[i]=y[i];非2整数幂可能会导致内存对齐效率低下,可能会导致编译器自动添加填充,以便在典型架构上正确对齐数据
现在我们已经了解了如何生成矢量化指令,让我们修改内存复制内核以使用矢量加载。
__global__ void device_copy_vector2_kernel(int* d_in, int* d_out, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
for (int i = idx; i < N/2; i += blockDim.x * gridDim.x) {
reinterpret_cast<int2*>(d_out)[i] = reinterpret_cast<int2*>(d_in)[i];
}
// in only one thread, process final element (if there is one)
if (idx==N/2 && N%2==1)
d_out[N-1] = d_in[N-1];
}
void device_copy_vector2(int* d_in, int* d_out, int n) {
threads = 256;
blocks = min((N/2 + threads-1) / threads, MAX_BLOCKS);
device_copy_vector2_kernel<<<blocks, threads>>>(d_in, d_out, N);
}这个内核只有一些变化。首先,循环现在只执行N/2次,因为每次迭代处理两个元素。其次,我们使用上述副本中的强制类型转换技术。第三,我们处理N不能被2整除时可能出现的任何剩余元素。最后,我们启动的线程数量是标量内核中的一半。
检查SASS,我们看到以下变化
...
LDG.E.64 R2, desc[UR4][R2.64] ;
...
STG.E.64 desc[UR4][R4.64], R2 ;
...请注意,现在编译器生成LDG.E.64和STG.E.64。所有其他指令都是一样的。然而,值得注意的是,由于循环只执行N/2次,因此执行的指令数量将减少一半。指令数的2倍改进在指令受限或延迟受限的内核中非常重要
我们还可以编写复制内核的vector4版本
__global__ void device_copy_vector4_kernel(int* d_in, int* d_out, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
for(int i = idx; i < N/4; i += blockDim.x * gridDim.x) {
reinterpret_cast<int4*>(d_out)[i] = reinterpret_cast<int4*>(d_in)[i];
}
// in only one thread, process final elements (if there are any)
int remainder = N%4;
if (idx==N/4 && remainder!=0) {
while(remainder) {
int idx = N - remainder--;
d_out[idx] = d_in[idx];
}
}
}
void device_copy_vector4(int* d_in, int* d_out, int N) {
int threads = 256;
int blocks = min((N/4 + threads-1) / threads, MAX_BLOCKS);
device_copy_vector4_kernel<<<blocks, threads>>>(d_in, d_out, N);
}相应的SASS变更包括以下内容
...
LDG.E.128 R4, desc[UR4][R4.64] ;
...
STG.E.128 desc[UR4][R8.64], R4 ;
...这里我们可以看到生成的LDG.E.128和STG.E.128。此版本的代码将指令数减少了四倍。您可以在下图中看到所有三个内核的整体性能
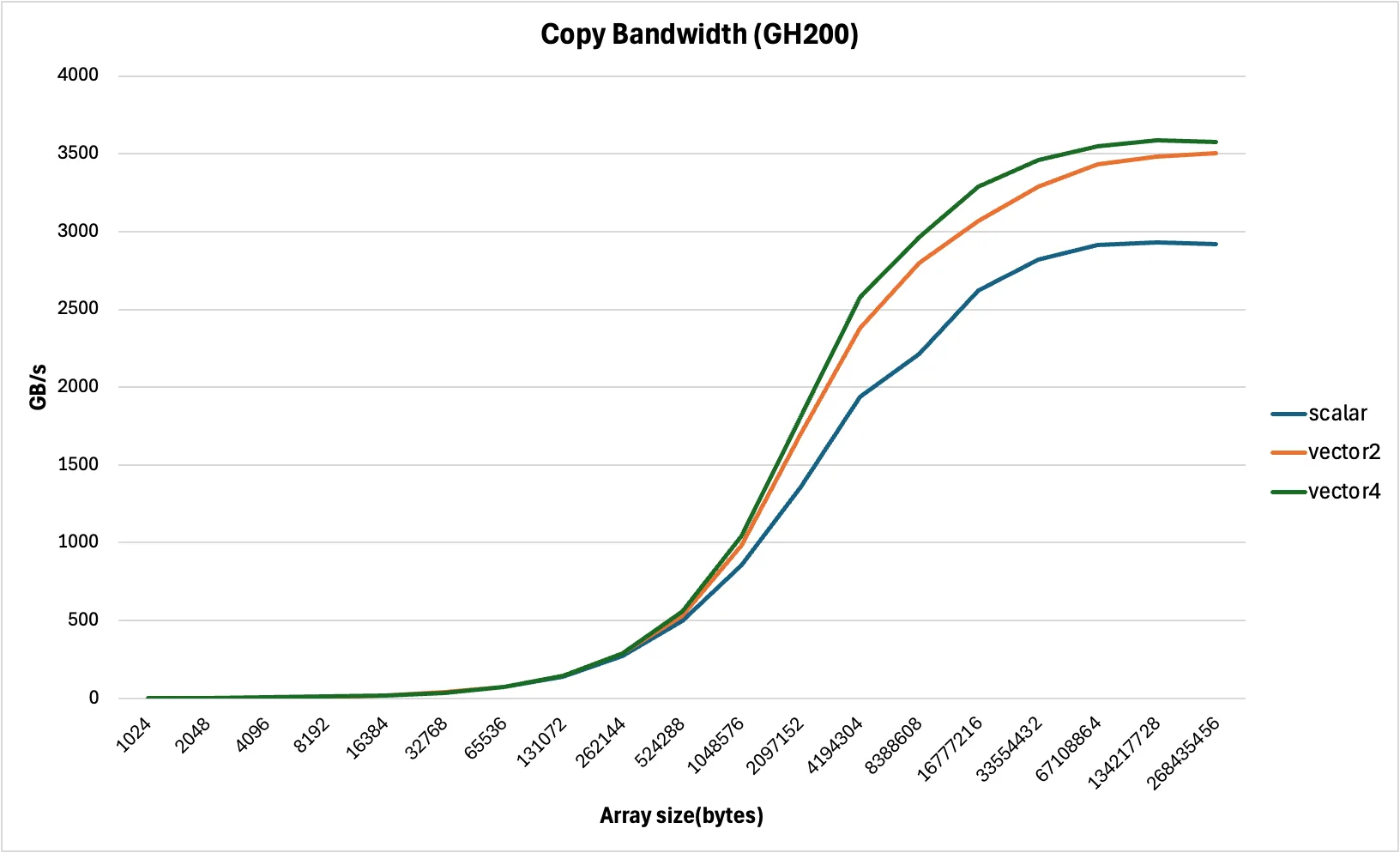
在几乎所有情况下,矢量化加载都比标量加载更可取。然而,请注意,使用矢量化加载会增加寄存器压力并降低整体并行性。因此,如果您的内核已经受到寄存器限制或并行性非常低,您可能希望坚持使用标量加载。此外,如前所述,如果指针未对齐或数据类型大小(以字节为单位)不是2的幂,则无法使用矢量化加载。
矢量化加载是一种基本的CUDA优化,您应该在可能的情况下使用,因为它们可以增加带宽、减少指令数和减少延迟。在这篇文章中,我展示了如何通过相对较少的更改轻松地将矢量化加载合并到现有的内核中。