PTX矩阵乘加指令详解
本文档描述了PTX(Parallel Thread Execution),一种低级并行线程执行虚拟机和指令集架构(ISA)。PTX将GPU暴露为数据并行计算设备。
指令描述的格式与语义
本节介绍每个PTX指令。除了指令的名称和格式外,还描述了语义,然后是一些示例,试图显示指令的几种可能实例化。
PTX指令
PTX指令通常有0到4个操作数,加上一个可选的保护谓词,出现在指令左侧的@符号后面
@p opcode;@p opcode a;@p opcode d, a;@p opcode d, a, b;@p opcode d, a, b, c;
Warp层级的矩阵乘加指令
矩阵乘加有以下格式
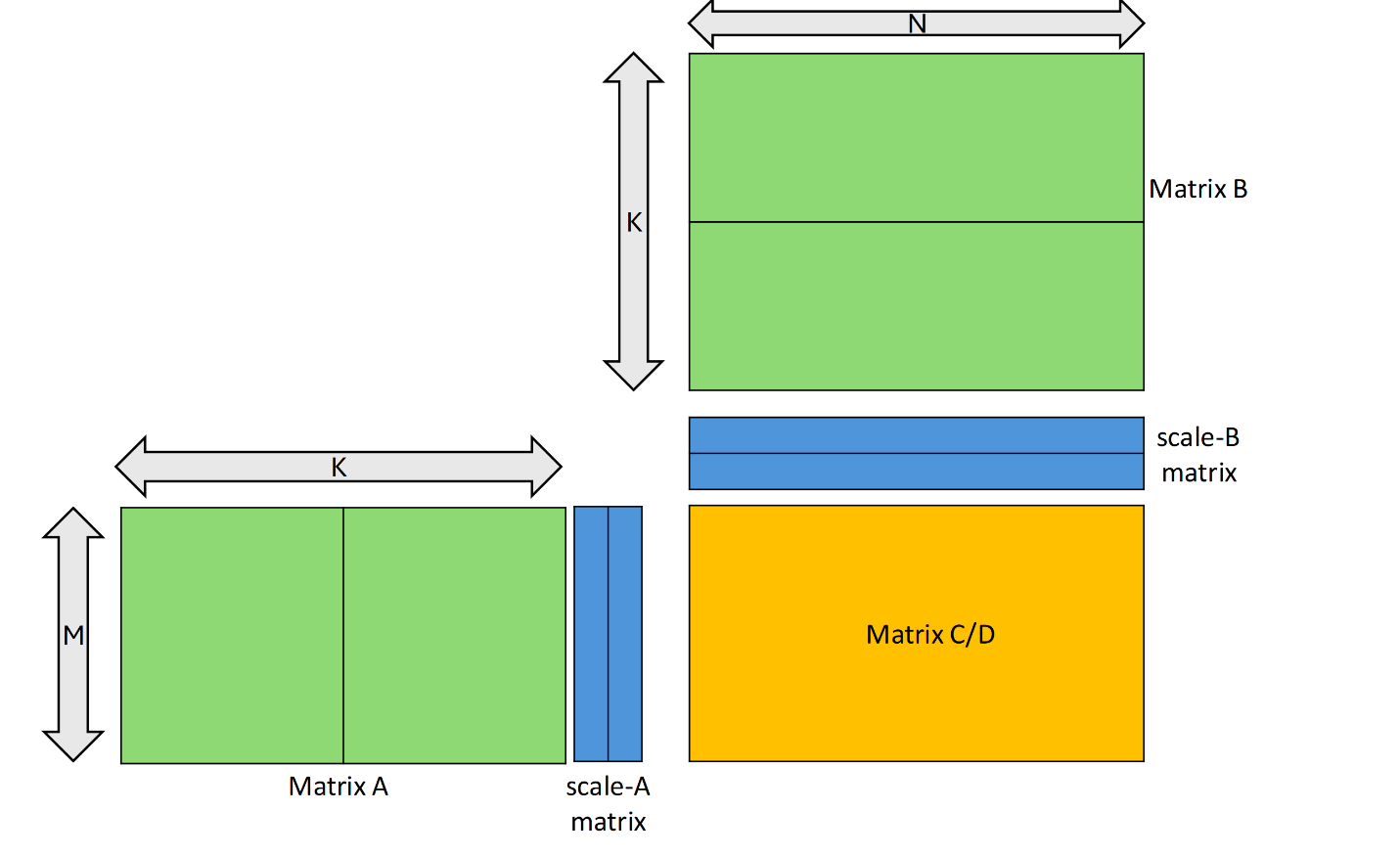
D = A * B + C其中D和C被称为累加器,并且可以是同一个矩阵
PTX提供了两种执行矩阵乘法和累加计算的方法
wmma指令
此warp级别计算由warp中的所有线程共同执行,如下所示:
用wmma.Load操作将矩阵A、B和C从内存加载到寄存器中。当操作完成时,每个线程中的目标寄存器都保存了加载矩阵的一个片段。
使用wmma.mma操作对加载的矩阵执行矩阵乘法和累加操作。当操作完成时,每个线程中的目标寄存器都保存着wmma.mma操作返回的结果矩阵的一个片段。
使用wmma.Store操作将结果矩阵D存储回内存。或者,结果矩阵D也可以用作后续wmma.mma操作的参数C。
wmma.load和wmma.store指令在从内存加载wmma.mma操作的输入矩阵以及将结果存储回内存时隐式处理矩阵元素的组织。
mma指令
与wmma类似,mma也要求warp中的所有线程共同执行计算,但是在调用mma操作之前,需要显式地完成warp中不同线程之间的矩阵元素分布。mma指令支持密集矩阵和稀疏矩阵A。当A是稀疏矩阵存储中描述的结构化稀疏矩阵时,可以使用稀疏变体。
https://arxiv.org/abs/2206.02874
矩阵形状
矩阵乘法和累加操作支持操作数矩阵A、B和C的有限形状集。所有三个矩阵操作数的形状由元组MxNxK共同描述,其中A是MxK矩阵,B是KxN矩阵,而C和D是MxN矩阵。
指定类型支持以下矩阵形状:
矩阵数据类型
矩阵乘法和累加操作在整数、浮点、半字节整数和单比特数据类型上分别支持。所有操作数必须包含相同的基本类型,即整数或浮点。
对于浮点矩阵乘法和累加操作,不同的矩阵操作数可能具有不同的精度,如稍后所述。
块缩放
mma指令有以下几种.kind限定符
.kind::mxf8f6f4.kind::mxf4.kind::mxf4nvf4
使用块缩放执行矩阵乘法。此操作具有以下形式:D=(A*scale_A)*(B*scale_B)+C
对于形状为M x SFA_N的scale_A矩阵,矩阵A的每一行被划分为SFA_N个块,每一行的块都与scale_A同一行的相应元素(以下称为SF_A)相乘
类似地,对于形状为SFB_M x N的scale_B矩阵,矩阵B的每一列被划分为SFB_M数量的块,并且列的每个块与scale_B的同一列中的相应元素(以下称为SF_B)相乘。
下图显示了一个块缩放为scale_vec::2X的mma示例
scale_A和scale_B矩阵的形状取决于限定符.scale_vec_size,如下表所示
下表列出了精确的元素类型和.scale_vec_size的有效组合
scale-a-data和scale-b-data参数分别为scale_a和scale_b矩阵提供元数据。
元组{byte-id-a,thread-id-a}和{byte-id-b,thread-id-b}提供选择器信息,以从相应的元数据参数scale-a-data和scale-b-data中选择元素SF_a和SF_b
元组{byte-id-a,thread-id-a}允许从scale-a-data中选择scale矩阵元素SF_a。同样,元组{byte-id-b,thread-id-b}允许从scale-b-data中选择scale矩阵元素SF_b
组件thread-id-a、thread-id-b决定了四元组中哪些线程贡献了SF_A和SF_A值。以下列表描述了线程选择器组件thread-id-a、thread-id-b的影响
由thread-id-a确定的四边形中的一个线程对贡献SF_a值。值0选择四边形中的下两个线程,而值1选择四边形的上两个线程。换句话说,当thread-id-a设置为0时,满足%laneid%4==0或1的线程对提供SF_a。相比之下,当thread-id-a设为1时,满足:%laneid%4==2或3的线程对则提供SF_a.更多详细信息请参考下图
laneid是线程在warp中的位置
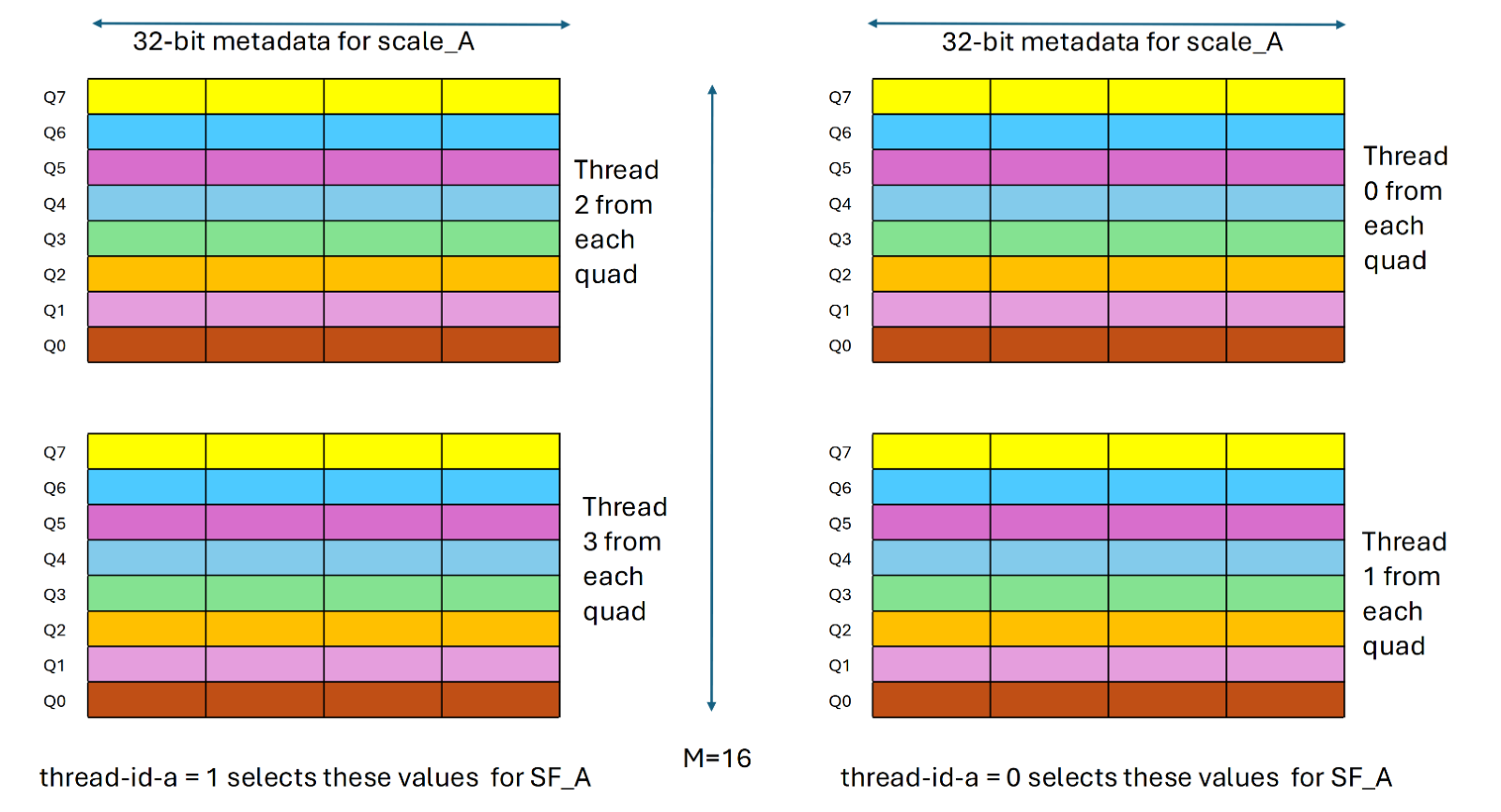
基于thread-id-a的SF_A值集的选择
由thread-id-b确定的四边形中的一个线程贡献了SF_B值。换句话说,每个满足%laneid%4==thread-id-b的线程都会提供SF_b。下图展示了详细信息:
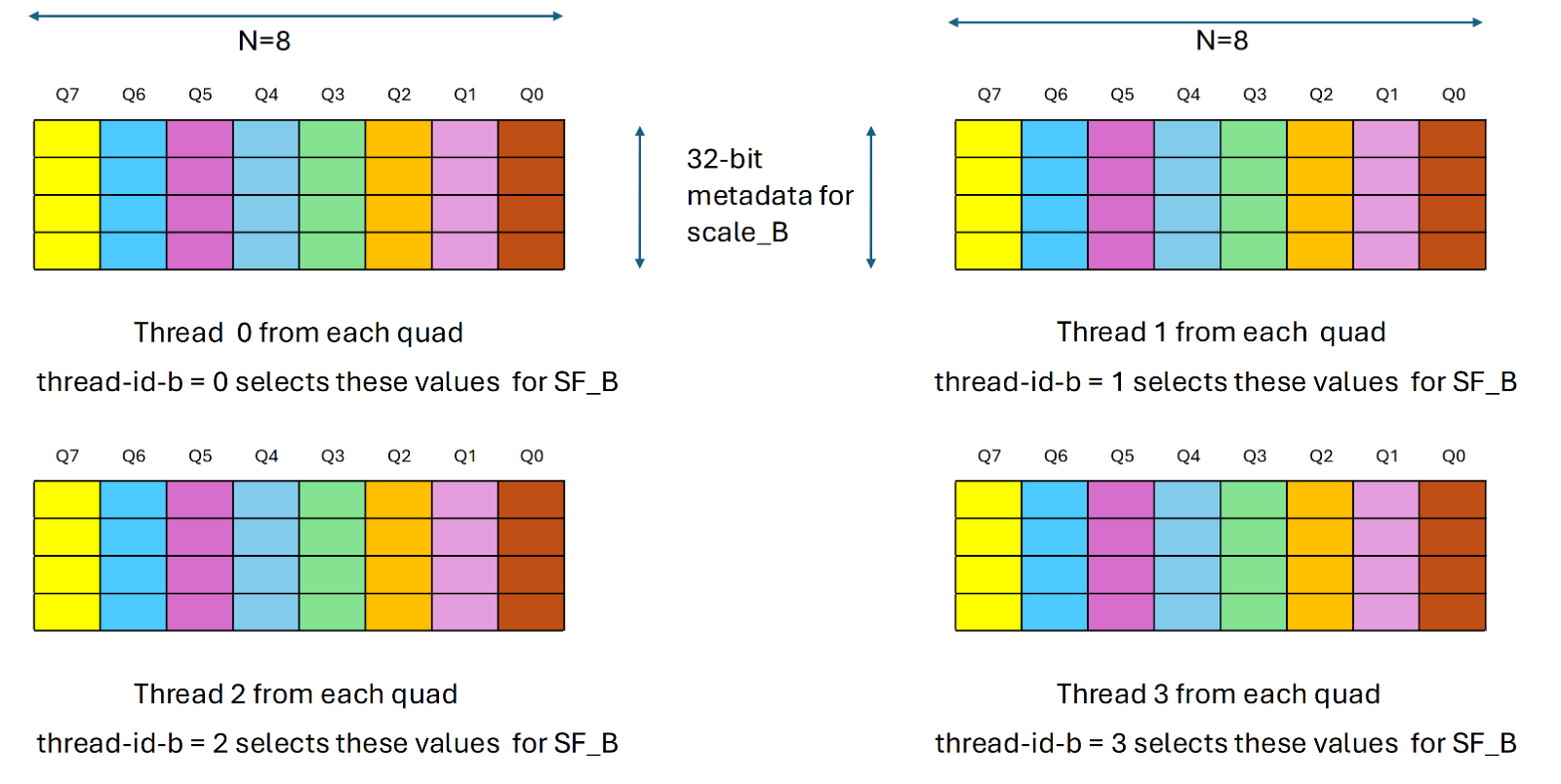
基于thread-id-b的SF_B值集的选择
参数byte-id-a、byte-id-b选择从scale-a-data、scale-b-data中贡献SF_a和SF_b值的字节。以下清单描述了.scale_vec_size限定符对字节选择器组件byte-id-a、byte-id-b的影响
当.scale_vec_size为.scale_vec时::1X
由byte-id-a、byte-id-b分别确定的scale-a-data和scale-b-data中的每个字节分别贡献SF_A和SF_B值。
当.scale_vec_size为.scale_vec时::2X
由byte-id-a和byte-id-b确定的scale-a-data和scale-b-data中的一个字节对(两个字节)贡献了SF_A和SF_B值。值0选择较低的两个字节,而值2从相应的元数据值中选择较高的两个比特。
3. 当.scale_vec_size为.scale_vec时::4X
scale-a-data和scale-b-data中的所有四个字节都贡献了这些值。因此,byte-id-a、byte-id-b必须为零。
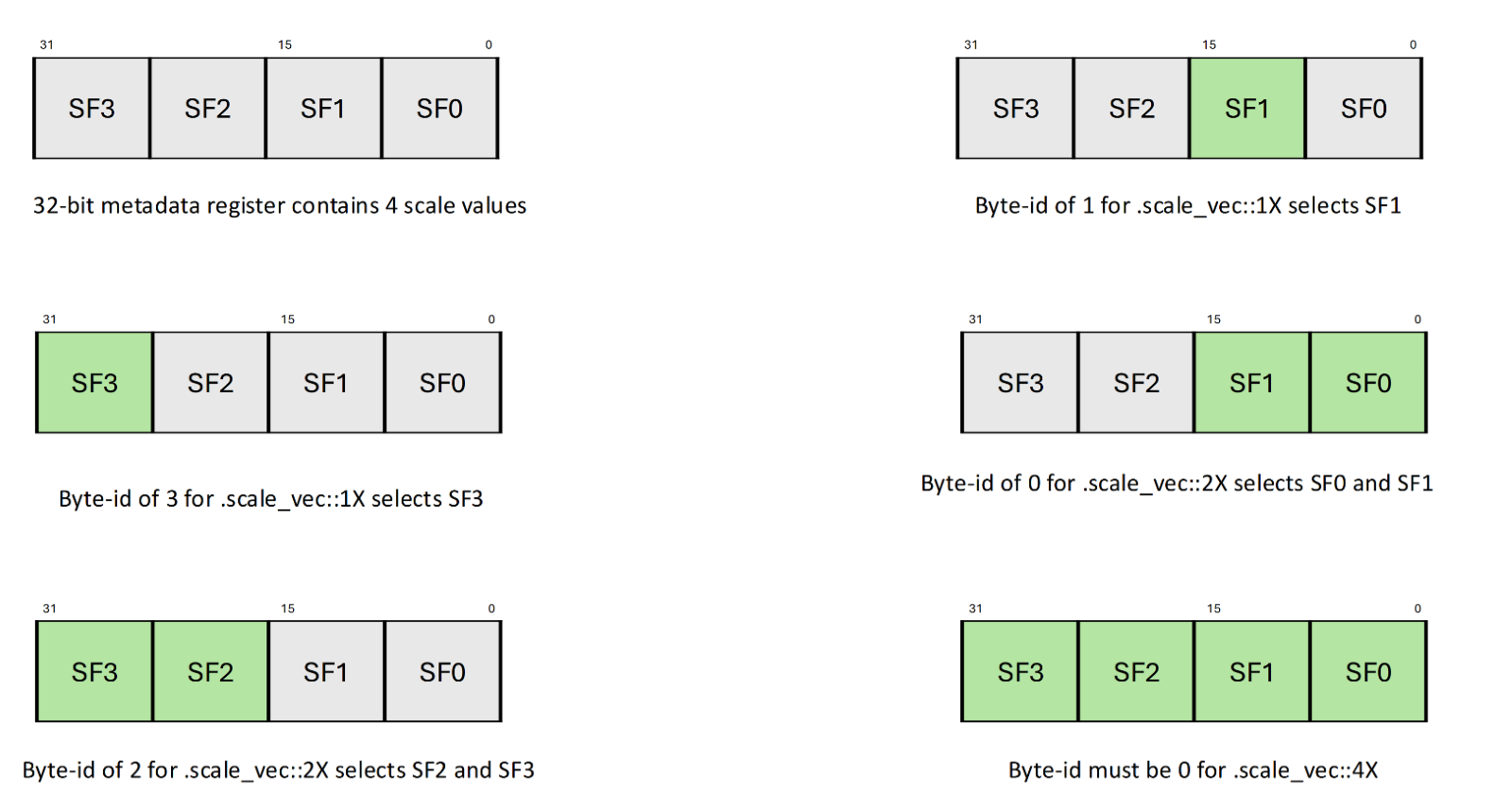
下表枚举各种选择器组件的有效值。任何其他值都会导致未定义的行为
使用wmma指令进行矩阵乘法累加运算
本节介绍warp级wmma.load、wmma.mma和wmma.store指令以及这些指令中涉及的各种矩阵的组织
WMMA中的矩阵分片
warp中的每个线程都保存着矩阵的一个片段。warp中线程加载的片段的分布是未指定的,并且依赖于目标架构,因此矩阵中片段的身份也是未指定的且依赖于目标体系架构的。如果基础矩阵的形状、布局和元素类型匹配,则wmma操作返回的片段可以用作另一个wmma操作的操作数。由于片段布局依赖于架构,如果两个函数链接在一起,但两个函数是针对兼容不同SM架构进行编译的,则将一个函数中的wmma操作返回的片段用作另一个函数的wmma运算的操作数可能无法按预期工作。请注意,将wmma片段传递给具有.leak链接的函数是不安全的,因为在链接时,对此类函数的引用可能会被解析为不同编译模块中的函数。
每个片段都是一个vector表达式,其内容确定如下。片段中单个矩阵元素的身份未指定。
整数分片
乘数A,B:
累加数C,D:
浮点数分片
.bf16数据类型浮点分片
乘数A,B:
累加数C,D:
.tf32数据类型浮点分片
双精度浮点数分片
半字节整型和单-bit分片
操纵片段内容
只要满足以下条件,就可以通过读写片段中的单个寄存器来操纵矩阵片段的内容
片段中的所有矩阵元素都使用相同的参数在线程间统一操作。
矩阵元素的顺序不变
例如,如果将与给定矩阵对应的每个寄存器乘以一个统一的常数值,则得到的矩阵就是原始矩阵的缩放版本。
请注意,在任一方向上都不支持.f16和.f32累加器片段之间的类型转换。即使片段中元素的顺序保持不变,结果也是未定义的。
WMMA中的矩阵存储
每个矩阵都可以以行主或列主布局存储在内存中。在行主格式中,每行的连续元素存储在连续的存储位置,该行称为矩阵的主导维度。在列主格式中,每列的连续元素存储在连续的存储位置,访列称为矩阵的主导维度。
主导维度(行或列)的连续实例不需要连续存储在内存中。wmma.load和wmma.store操作接受一个可选参数stride,该参数指定从每行(或列)的开头到下一行的偏移量,以矩阵元素(而不是字节)表示。例如,通过wmma操作访问的矩阵可能是存储在内存中的较大矩阵的子矩阵。这允许程序员对大于wmma操作支持的形状的矩阵进行乘法和累加操作。
主导维度(行或列)的每个实例的起始地址必须与相应片段的大小(以字节为单位)对齐。请注意,起始地址由基指针和可选步幅决定。
考虑下面的例子:
wmma.load.a.sync.aligned.row.m16n16k16.f16 {x0,...,x7}, [p], s;片段大小(字节)=32(八个.f16x2类型的元素)
实际步幅(字节)=2*s(因为步幅是用.f16元素指定的,而不是字节)
对于要以片段大小对齐的矩阵的每一行,必须满足以下条件:
p是32的倍数。
2*s是32的倍数。
stride的默认值
步幅的默认值是矩阵前导维度的大小。例如,对于MxK矩阵,行主布局的步幅为K,列主布局的步距为M。特别是,支持的矩阵形状的默认步幅如下:
Warp级矩阵加载指令: wmma.load
wmma.load
从内存中为WMMA联合加载矩阵
语法
.f16加载
wmma.load.a.sync.aligned.layout.shape{.ss}.atype r, [p] {, stride};
wmma.load.b.sync.aligned.layout.shape{.ss}.btype r, [p] {, stride};
wmma.load.c.sync.aligned.layout.shape{.ss}.ctype r, [p] {, stride};
.layout = {.row, .col};
.shape = {.m16n16k16, .m8n32k16, .m32n8k16};
.ss = {.global, .shared{::cta}};
.atype = {.f16, .s8, .u8};
.btype = {.f16, .s8, .u8};
.ctype = {.f16, .f32, .s32};.bf16加载
wmma.load.a.sync.aligned.layout.shape{.ss}.atype r, [p] {, stride}
wmma.load.b.sync.aligned.layout.shape{.ss}.btype r, [p] {, stride}
wmma.load.c.sync.aligned.layout.shape{.ss}.ctype r, [p] {, stride}
.layout = {.row, .col};
.shape = {.m16n16k16, .m8n32k16, .m32n8k16};
.ss = {.global, .shared{::cta}};
.atype = {.bf16 };
.btype = {.bf16 };
.ctype = {.f32 };.tf32加载
wmma.load.a.sync.aligned.layout.shape{.ss}.atype r, [p] {, stride}
wmma.load.b.sync.aligned.layout.shape{.ss}.btype r, [p] {, stride}
wmma.load.c.sync.aligned.layout.shape{.ss}.ctype r, [p] {, stride}
.layout = {.row, .col};
.shape = {.m16n16k8 };
.ss = {.global, .shared{::cta}};
.atype = {.tf32 };
.btype = {.tf32 };
.ctype = {.f32 };.f64加载
wmma.load.a.sync.aligned.layout.shape{.ss}.atype r, [p] {, stride}
wmma.load.b.sync.aligned.layout.shape{.ss}.btype r, [p] {, stride}
wmma.load.c.sync.aligned.layout.shape{.ss}.ctype r, [p] {, stride}
.layout = {.row, .col};
.shape = {.m8n8k4 };
.ss = {.global, .shared{::cta}};
.atype = {.f64 };
.btype = {.f64 };
.ctype = {.f64 };半字节加载
wmma.load.a.sync.aligned.row.shape{.ss}.atype r, [p] {, stride}
wmma.load.b.sync.aligned.col.shape{.ss}.btype r, [p] {, stride}
wmma.load.c.sync.aligned.layout.shape{.ss}.ctype r, [p] {, stride}
.layout = {.row, .col};
.shape = {.m8n8k32};
.ss = {.global, .shared{::cta}};
.atype = {.s4, .u4};
.btype = {.s4, .u4};
.ctype = {.s32};单bit加载
wmma.load.a.sync.aligned.row.shape{.ss}.atype r, [p] {, stride}
wmma.load.b.sync.aligned.col.shape{.ss}.btype r, [p] {, stride}
wmma.load.c.sync.aligned.layout.shape{.ss}.ctype r, [p] {, stride}
.layout = {.row, .col};
.shape = {.m8n8k128};
.ss = {.global, .shared{::cta}};
.atype = {.b1};
.btype = {.b1};
.ctype = {.s32};描述
从指定状态空间中地址操作数p指示的位置,在warp中的所有线程上共同加载一个矩阵到目标寄存器r中
如果没有给出状态空间,会执行通用寻址执行内存访问。wmma.load操作只能与.global和.shared空间以及通用寻址一起使用,其中地址指向.global或.shared空间。
互斥限定符.a、.b和.c分别指示是否正在为wmma计算加载矩阵a、b或c。
目标操作数r是一个括号括起来的向量表达式,可以保存加载操作返回的片段,如WMMA的矩阵片段中所述。
.shape限定符表示预期wmma计算中涉及的所有矩阵参数的维度
layout限定符指示要加载的矩阵是以行主格式还是列主格式存储的
stride是一个可选的32位整数操作数,它在前导维度(行或列)的连续实例的开始之间提供矩阵元素的偏移。WMMA的矩阵存储中描述了步幅的默认值,如果实际值大于默认值,则必须指定。例如,如果矩阵是较大矩阵的子矩阵,则步幅的值是该较大矩阵的前导维度。指定低于默认值的值会导致未定义的行为
WMMA的矩阵存储中描述了地址p和步幅所需的对齐
强制的.sync限定符表示wmma.load会导致执行线程等待,直到warp中的所有线程执行相同的wmma.looad指令,然后再恢复执行。
强制性的.aliged限定符表示warp中的所有线程必须执行相同的wmma.load指令。在有条件执行的代码中,只有当知道warp中的所有线程都以相同的方式计算条件时,才应使用wmma.load指令,否则行为未定义。
如果所有线程都不使用相同的限定符和相同的p和stride值,或者如果warp中的任何线程都已退出,则wmma.load的行为是未定义的
在内存一致性模型中,wmma.load被视为弱内存操作
PTX ISA Note
在PTX ISA 6.0版本中引入。
PTX ISA 6.1版中引入的.m8n32k16和.m32n8k16。
PTX ISA 6.3版引入了整数、子字节整数和单比特wmma。
PTX ISA 7.0版中引入的wmma上的.m8n8k4和.m16n16k8。
PTX ISA 7.0版引入了双精度和交替浮点精度wmma。
从PTX ISA 6.3版开始,需要使用修饰符.
aligned,在小于6.3的PTX ISA版本中,这被认为是隐含的。支持PTX ISA 7.8版中引入的:cta子限定符。
预览功能
半字节wmma和单比特wmma是PTX ISA 6.3版的预览功能。所有细节都可能发生变化,并不保证未来PTX ISA版本或SM架构的向后兼容性
目标ISA Note
浮点wmma要求sm_70或更高
整数wmma要求sm_72或更高
子字节和单比特wmma要求sm_75或更高
双精度和交替浮点精度wmma需要sm_80或更高
举例:
// Load elements from f16 row-major matrix B
.reg .b32 x<8>;
wmma.load.b.sync.aligned.m16n16k16.row.f16 {x0,x1,x2,x3,x4,x5,x,x7}, [ptr];
// Now use {x0, ..., x7} for the actual wmma.mma
// Load elements from f32 column-major matrix C and scale the values:
.reg .b32 x<8>;
wmma.load.c.sync.aligned.m16n16k16.col.f32
{x0,x1,x2,x3,x4,x5,x6,x7}, [ptr];
mul.f32 x0, x0, 0.1;
// repeat for all registers x<8>;
...
mul.f32 x7, x7, 0.1;
// Now use {x0, ..., x7} for the actual wmma.mma
// Load elements from integer matrix A:
.reg .b32 x<4>
// destination registers x<4> contain four packed .u8 values each
wmma.load.a.sync.aligned.m32n8k16.row.u8 {x0,x1,x2,x3}, [ptr];
// Load elements from sub-byte integer matrix A:
.reg .b32 x0;
// destination register x0 contains eight packed .s4 values
wmma.load.a.sync.aligned.m8n8k32.row.s4 {x0}, [ptr];
// Load elements from .bf16 matrix A:
.reg .b32 x<4>;
wmma.load.a.sync.aligned.m16n16k16.row.bf16
{x0,x1,x2,x3}, [ptr];
// Load elements from .tf32 matrix A:
.reg .b32 x<4>;
wmma.load.a.sync.aligned.m16n16k8.row.tf32
{x0,x1,x2,x3}, [ptr];
// Load elements from .f64 matrix A:
.reg .b32 x<4>;
wmma.load.a.sync.aligned.m8n8k4.row.f64
{x0}, [ptr];Warp-level Matrix Store Instruction: wmma.store
wmma.store
Collectively store a matrix into memory for WMMA
Syntax
wmma.store.d.sync.aligned.layout.shape{.ss}.type [p], r {, stride};
.layout = {.row, .col};
.shape = {.m16n16k16, .m8n32k16, .m32n8k16};
.ss = {.global, .shared{::cta}};
.type = {.f16, .f32, .s32};
wmma.store.d.sync.aligned.layout.shape{.ss}.type [p], r {, stride}
.layout = {.row, .col};
.shape = {.m8n8k32, .m8n8k128};
.ss = {.global, .shared{::cta}};
.type = {.s32};
wmma.store.d.sync.aligned.layout.shape{.ss}.type [p], r {, stride}
.layout = {.row, .col};
.shape = {.m16n16k8};
.ss = {.global, .shared{::cta}};
.type = {.f32};
wmma.store.d.sync.aligned.layout.shape{.ss}.type [p], r {, stride}
.layout = {.row, .col};
.shape = {.m8n8k4 };
.ss = {.global, .shared{::cta}};
.type = {.f64};
Description
Collectively store a matrix across all threads in a warp at the location indicated by address operand p in the specified state space from source register r.
If no state space is given, perform the memory accesses using Generic Addressing. wmma.load operation may be used only with .global and .shared spaces and with generic addressing, where the address points to .global or .shared space.
The source operand r is a brace-enclosed vector expression that matches the shape of the fragment expected by the store operation, as described in Matrix Fragments for WMMA.
The .shape qualifier indicates the dimensions of all the matrix arguments involved in the intended wmma computation. It must match the .shape qualifier specified on the wmma.mma instruction that produced the D matrix being stored.
The .layout qualifier indicates whether the matrix to be loaded is stored in row-major or column-major format.
stride is an optional 32-bit integer operand that provides an offset in terms of matrix elements between the start of consecutive instances of the leading dimension (rows or columns). The default value of stride is described in Matrix Storage for WMMA and must be specified if the actual value is larger than the default. For example, if the matrix is a sub-matrix of a larger matrix, then the value of stride is the leading dimension of the larger matrix. Specifying a value lower than the default value results in undefined behavior.
The required alignment for address p and stride is described in the Matrix Storage for WMMA.
The mandatory .sync qualifier indicates that wmma.store causes the executing thread to wait until all threads in the warp execute the same wmma.store instruction before resuming execution.
The mandatory .aligned qualifier indicates that all threads in the warp must execute the same wmma.store instruction. In conditionally executed code, a wmma.store instruction should only be used if it is known that all threads in the warp evaluate the condition identically, otherwise behavior is undefined.
The behavior of wmma.store is undefined if all threads do not use the same qualifiers and the same values of p and stride, or if any thread in the warp has exited.
wmma.store is treated as a weak memory operation in the Memory Consistency Model.
PTX ISA Notes
Introduced in PTX ISA version 6.0.
.m8n32k16 and .m32n8k16 introduced in PTX ISA version 6.1.
Integer, sub-byte integer and single-bit wmma introduced in PTX ISA version 6.3.
.m16n16k8 introduced in PTX ISA version 7.0.
Double precision wmma introduced in PTX ISA version 7.0.
Modifier .aligned is required from PTX ISA version 6.3 onwards, and considered implicit in PTX ISA versions less than 6.3.
Support for ::cta sub-qualifier introduced in PTX ISA version 7.8.
Preview Feature:
Sub-byte wmma and single-bit wmma are preview features in PTX ISA version 6.3. All details are subject to change with no guarantees of backward compatibility on future PTX ISA versions or SM architectures.
Target ISA Notes
Floating point wmma requires sm_70 or higher.
Integer wmma requires sm_72 or higher.
Sub-byte and single-bit wmma requires sm_75 or higher.
Double precision wmma and shape .m16n16k8 requires sm_80 or higher.
Examples
// Storing f32 elements computed by a wmma.mma
.reg .b32 x<8>;
wmma.mma.sync.m16n16k16.row.col.f32.f32
{d0, d1, d2, d3, d4, d5, d6, d7}, ...;
wmma.store.d.sync.m16n16k16.row.f32
[ptr], {d0, d1, d2, d3, d4, d5, d6, d7};
// Store s32 accumulator for m16n16k16 shape:
.reg .b32 d<8>;
wmma.store.d.sync.aligned.m16n16k16.row.s32
[ptr], {d0, d1, d2, d3, d4, d5, d6, d7};
// Store s32 accumulator for m8n8k128 shape:
.reg .b32 d<2>
wmma.store.d.sync.aligned.m8n8k128.row.s32
[ptr], {d0, d1};
// Store f64 accumulator for m8n8k4 shape:
.reg .f64 d<2>;
wmma.store.d.sync.aligned.m8n8k4.row.f64
[ptr], {d0, d1};warp级矩阵乘法累加指令:wmma.mma
wmma.mma
跨warp执行单个矩阵乘法和累加操作
Syntax
// Floating point (.f16 multiplicands) wmma.mma
wmma.mma.sync.aligned.alayout.blayout.shape.dtype.ctype d, a, b, c;
// Integer (.u8/.s8 multiplicands) wmma.mma
wmma.mma.sync.aligned.alayout.blayout.shape.s32.atype.btype.s32{.satfinite} d, a, b, c;
.alayout = {.row, .col};
.blayout = {.row, .col};
.shape = {.m16n16k16, .m8n32k16, .m32n8k16};
.dtype = {.f16, .f32};
.atype = {.s8, .u8};
.btype = {.s8, .u8};
.ctype = {.f16, .f32};
Floating point format .bf16 wmma.mma:
wmma.mma.sync.aligned.alayout.blayout.shape.f32.atype.btype.f32 d, a, b, c;
.alayout = {.row, .col};
.blayout = {.row, .col};
.shape = {.m16n16k16, .m8n32k16, .m32n8k16};
.atype = {.bf16 };
.btype = {.bf16};
Floating point format .tf32 wmma.mma:
wmma.mma.sync.aligned.alayout.blayout.shape.f32.atype.btype.f32 d, a, b, c;
.alayout = {.row, .col};
.blayout = {.row, .col};
.shape = {.m16n16k8 };
.atype = {.tf32 };
.btype = {.tf32};
Floating point Double precision wmma.mma:
wmma.mma.sync.aligned.alayout.blayout.shape{.rnd}.f64.f64.f64.f64 d, a, b, c;
.alayout = {.row, .col};
.blayout = {.row, .col};
.shape = {.m8n8k4 };
.rnd = { .rn, .rz, .rm, .rp };
Sub-byte (.u4/.s4 multiplicands) wmma.mma:
wmma.mma.sync.aligned.row.col.shape.s32.atype.btype.s32{.satfinite} d, a, b, c;
.shape = {.m8n8k32};
.atype = {.s4, .u4};
.btype = {.s4, .u4};
Single-bit (.b1 multiplicands) wmma.mma:
wmma.mma.op.popc.sync.aligned.row.col.shape.s32.atype.btype.s32 d, a, b, c;
.shape = {.m8n8k128};
.atype = {.b1};
.btype = {.b1};
.op = {.xor, .and}
Description
Perform a warp-level matrix multiply-and-accumulate computation D = A * B + C using matrices A, B and C loaded in registers a, b and c respectively, and store the result matrix in register d. The register arguments a, b, c and d hold unspecified fragments of the corresponding matrices as described in Matrix Fragments for WMMA
The qualifiers .dtype, .atype, .btype and .ctype indicate the data-type of the elements in the matrices D, A, B and C respectively.
For wmma.mma without explicit .atype and .btype: .atype and .btype are implicitly set to .f16.
For integer wmma, .ctype and .dtype must be specified as .s32. Also, the values for .atype and .btype must be the same, i.e., either both are .s8 or both are .u8.
For sub-byte single-bit wmma, .ctype and .dtype must be specified as .s32. Also, the values for .atype and .btype must be the same; i.e., either both are .s4, both are .u4, or both are .b1.
For single-bit wmma, multiplication is replaced by a sequence of logical operations; specifically, wmma.xor.popc and wmma.and.popc computes the XOR, AND respectively of a 128-bit row of A with a 128-bit column of B, then counts the number of set bits in the result (popc). This result is added to the corresponding element of C and written into D.
The qualifiers .alayout and .blayout must match the layout specified on the wmma.load instructions that produce the contents of operands a and b respectively. Similarly, the qualifiers .atype, .btype and .ctype must match the corresponding qualifiers on the wmma.load instructions that produce the contents of operands a, b and c respectively.
The .shape qualifier must match the .shape qualifier used on the wmma.load instructions that produce the contents of all three input operands a, b and c respectively.
The destination operand d is a brace-enclosed vector expression that matches the .shape of the fragment computed by the wmma.mma instruction.
Saturation at the output:
The optional qualifier .satfinite indicates that the final values in the destination register are saturated as follows:
The output is clamped to the minimum or maximum 32-bit signed integer value. Otherwise, if the accumulation would overflow, the value wraps.
Precision and rounding for .f16 floating point operations:
Element-wise multiplication of matrix A and B is performed with at least single precision. When .ctype or .dtype is .f32, accumulation of the intermediate values is performed with at least single precision. When both .ctype and .dtype are specified as .f16, the accumulation is performed with at least half precision.
The accumulation order, rounding and handling of subnormal inputs is unspecified.
Precision and rounding for .bf16, .tf32 floating point operations:
Element-wise multiplication of matrix A and B is performed with specified precision. Accumulation of the intermediate values is performed with at least single precision.
The accumulation order, rounding and handling of subnormal inputs is unspecified.
Rounding modifiers on double precision wmma.mma (default is .rn):
.rn
mantissa LSB rounds to nearest even
.rz
mantissa LSB rounds towards zero
.rm
mantissa LSB rounds towards negative infinity
.rp
mantissa LSB rounds towards positive infinity
The mandatory .sync qualifier indicates that wmma.mma causes the executing thread to wait until all threads in the warp execute the same wmma.mma instruction before resuming execution.
The mandatory .aligned qualifier indicates that all threads in the warp must execute the same wmma.mma instruction. In conditionally executed code, a wmma.mma instruction should only be used if it is known that all threads in the warp evaluate the condition identically, otherwise behavior is undefined.
The behavior of wmma.mma is undefined if all threads in the same warp do not use the same qualifiers, or if any thread in the warp has exited.
PTX ISA Notes
Introduced in PTX ISA version 6.0.
.m8n32k16 and .m32n8k16 introduced in PTX ISA version 6.1.
Integer, sub-byte integer and single-bit wmma introduced in PTX ISA version 6.3.
Double precision and alternate floating point precision wmma introduced in PTX ISA version 7.0.
Support for .and operation in single-bit wmma introduced in PTX ISA version 7.1.
Modifier .aligned is required from PTX ISA version 6.3 onwards, and considered implicit in PTX ISA versions less than 6.3.
Support for .satfinite on floating point wmma.mma is deprecated in PTX ISA version 6.4 and is removed from PTX ISA version 6.5.
Preview Feature:
Sub-byte wmma and single-bit wmma are preview features in PTX ISA. All details are subject to change with no guarantees of backward compatibility on future PTX ISA versions or SM architectures.
Target ISA Notes
Floating point wmma requires sm_70 or higher.
Integer wmma requires sm_72 or higher.
Sub-byte and single-bit wmma requires sm_75 or higher.
Double precision, alternate floating point precision wmma require sm_80 or higher.
.and operation in single-bit wmma requires sm_80 or higher.
Examples
.global .align 32 .f16 A[256], B[256];
.global .align 32 .f32 C[256], D[256];
.reg .b32 a<8> b<8> c<8> d<8>;
wmma.load.a.sync.aligned.m16n16k16.global.row.f16
{a0, a1, a2, a3, a4, a5, a6, a7}, [A];
wmma.load.b.sync.aligned.m16n16k16.global.col.f16
{b0, b1, b2, b3, b4, b5, b6, b7}, [B];
wmma.load.c.sync.aligned.m16n16k16.global.row.f32
{c0, c1, c2, c3, c4, c5, c6, c7}, [C];
wmma.mma.sync.aligned.m16n16k16.row.col.f32.f32
{d0, d1, d2, d3, d4, d5, d6, d7},
{a0, a1, a2, a3, a4, a5, a6, a7},
{b0, b1, b2, b3, b4, b5, b6, b7},
{c0, c1, c2, c3, c4, c5, c6, c7};
wmma.store.d.sync.aligned.m16n16k16.global.col.f32
[D], {d0, d1, d2, d3, d4, d5, d6, d7};
// Compute an integer WMMA:
.reg .b32 a, b<4>;
.reg .b32 c<8>, d<8>;
wmma.mma.sync.aligned.m8n32k16.row.col.s32.s8.s8.s32
{d0, d1, d2, d3, d4, d5, d6, d7},
{a}, {b0, b1, b2, b3},
{c0, c1, c2, c3, c4, c5, c6, c7};
// Compute sub-byte WMMA:
.reg .b32 a, b, c<2> d<2>
wmma.mma.sync.aligned.m8n8k32.row.col.s32.s4.s4.s32
{d0, d1}, {a}, {b}, {c0, c1};
// Compute single-bit type WMMA:
.reg .b32 a, b, c<2> d<2>
wmma.mma.xor.popc.sync.aligned.m8n8k128.row.col.s32.b1.b1.s32
{d0, d1}, {a}, {b}, {c0, c1};
// Compute double precision wmma
.reg .f64 a, b, c<2>, d<2>;
wmma.mma.sync.aligned.m8n8k4.row.col.f64.f64.f64.f64
{d0, d1}, {a}, {b}, {c0, c1};
// Compute alternate floating point precision wmma
.reg .b32 a<2>, b<2>, c<8>, d<8>;
wmma.mma.sync.aligned.m16n16k8.row.col.f32.tf32.tf32.f32
{d0, d1, d2, d3, d4, d5, d6, d7},
{a0, a1, a2, a3}, {b0, b1, b2, b3},
{c0, c1, c2, c3, c4, c5, c6, c7};使用mma指令实现矩阵乘加
本节介绍warp级mma、ldmatrix、stmatrix和movmatrix指令,以及这些指令中涉及的各种矩阵的组织
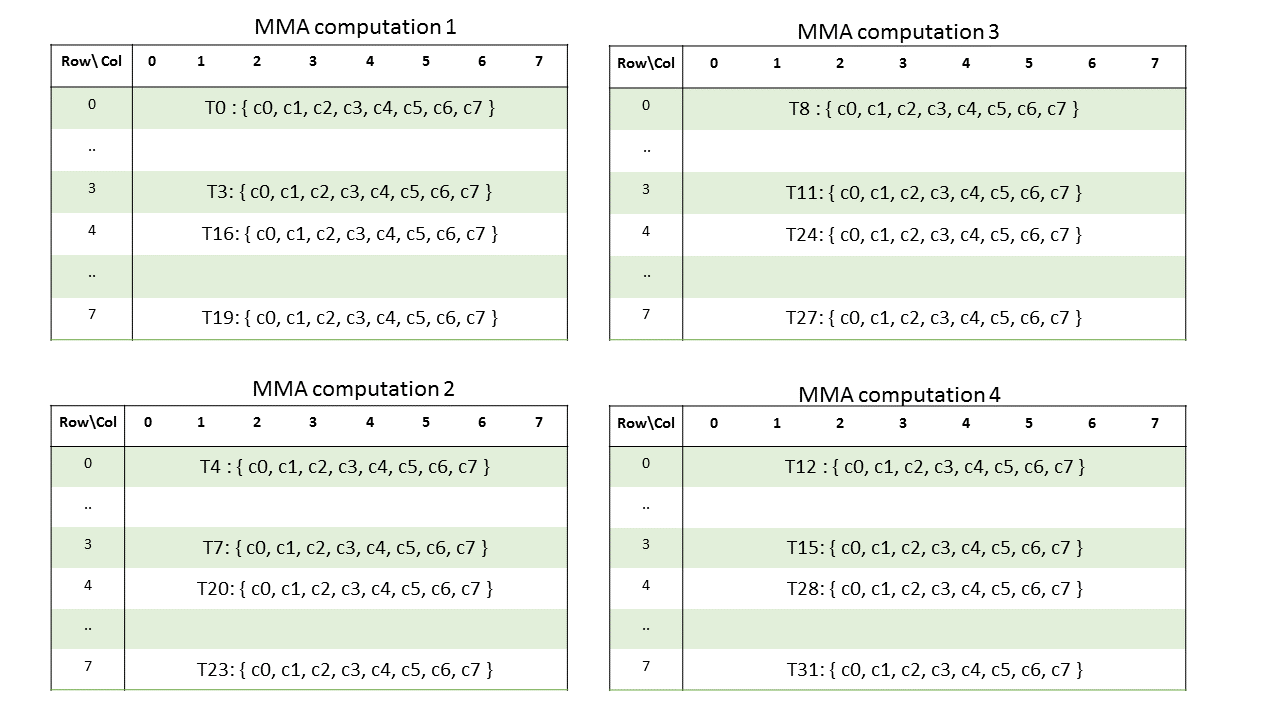
执行具有.f16浮点类型的mma.m8n8k4的warp将计算4个形状为.m8n8k4的mma操作
4个矩阵的元素需要分布在warp中的线程上。下表显示了MMA操作的矩阵分布
对于上面显示的每个单独的MMA计算,每个所需的线程都包含一个矩阵片段,用于执行MMA操作,如下所示
乘数A
不同线程所持分片的布局如下所示
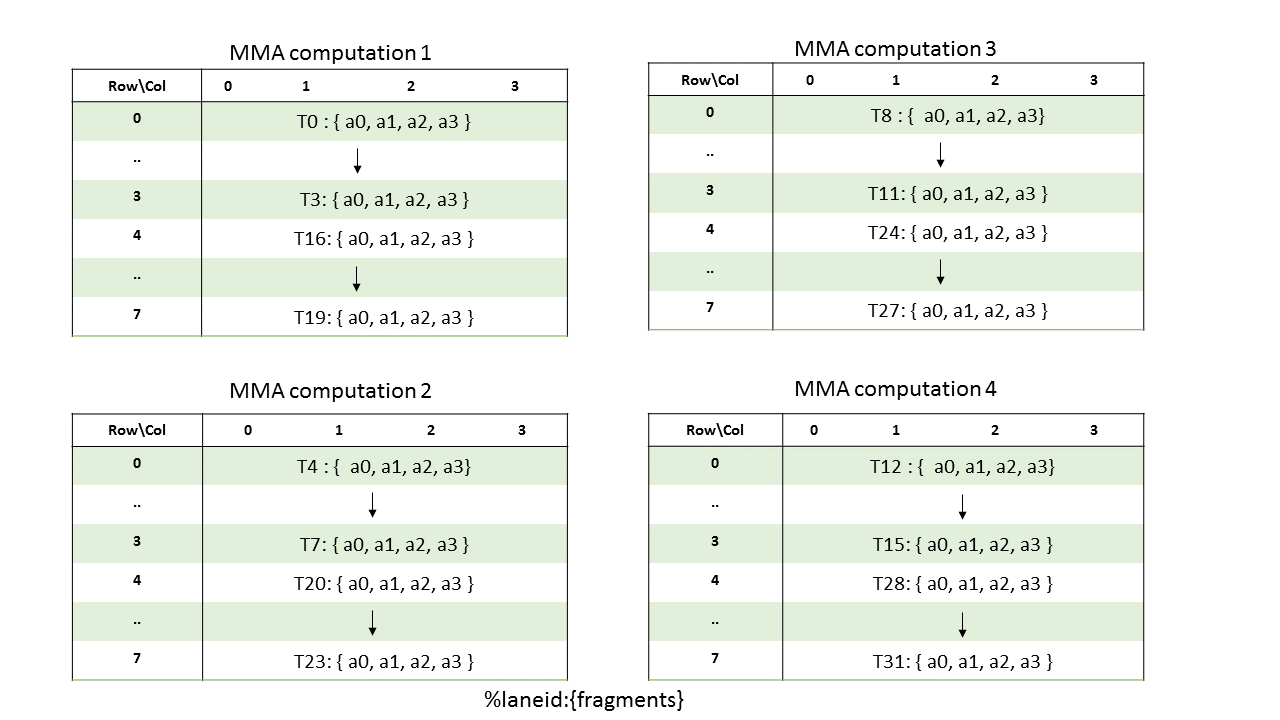
矩阵片段行和列的计算公式如下:
row = %laneid % 4 if %laneid < 16
(%laneid % 4) + 4 otherwise
col = i for ai where i = {0,..,3}列主矩阵A的分片布局如下所示
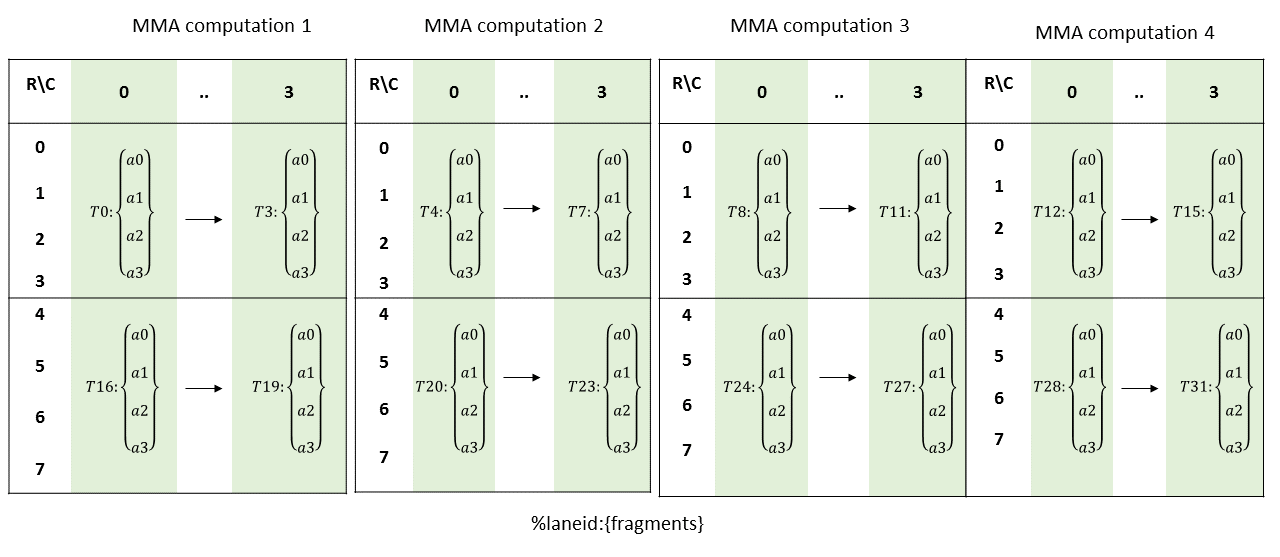
计算公式如下:
row = i % 4 for ai where i = {0,..,3} if %laneid < 16
(i % 4) + 4 for ai where i = {0,..,3} otherwise
col = %laneid % 4乘数矩阵B:
行主矩阵B的片段布局如下图所示
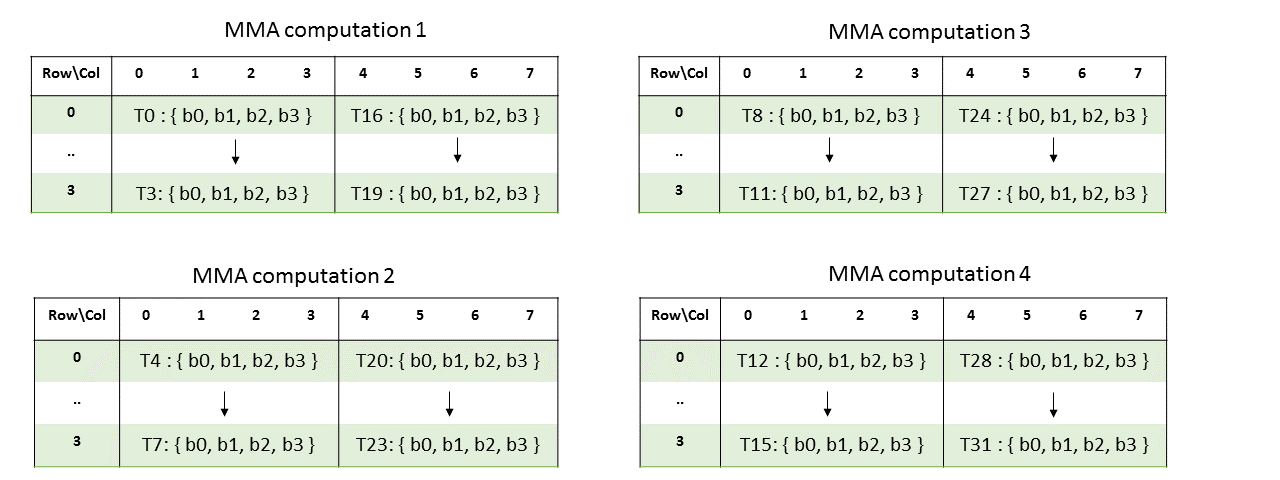
计算公式如下:
row = %laneid % 4
col = i for bi where i = {0,..,3} if %laneid < 16
i+4 for bi where i = {0,..,3} otherwise列主矩阵B的片段布局如下图所示
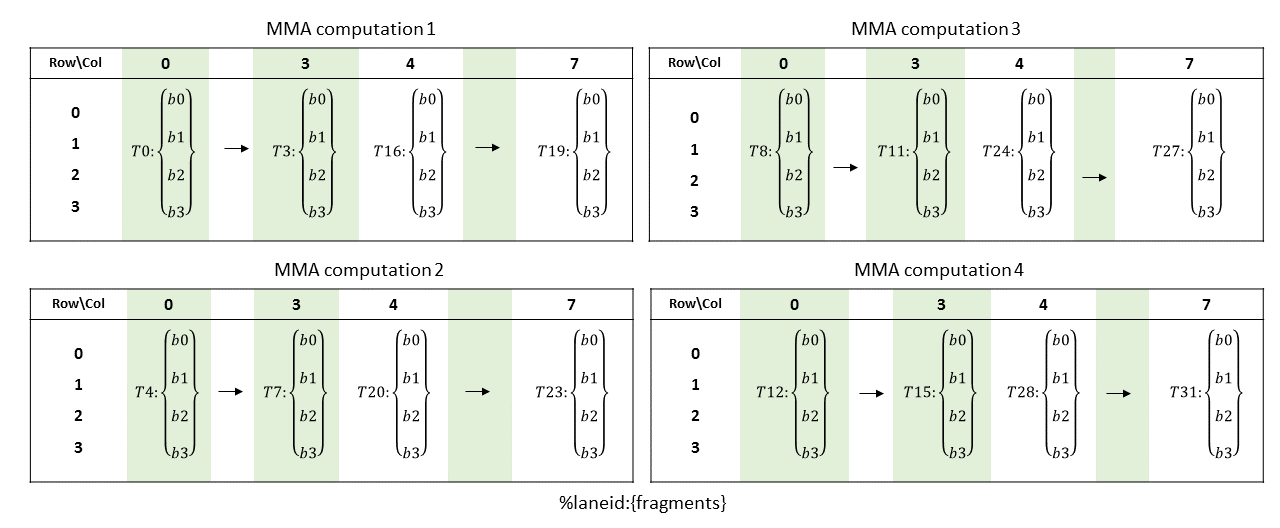
计算公式如下:
row = i for bi where i = {0,..,3}
col = %laneid % 4 if %laneid < 16
(%laneid % 4) + 4 otherwise累加器(C或D)
数据类型为.f16时不同线程的分片矩阵如下图所示
计算公式如下:
row = %laneid % 4 if %laneid < 16
(%laneid % 4) + 4 otherwise
col = i for ci where i = {0,..,7}
数据类型为.f32时的布局如下:


计算公式如下:
row = X if %laneid < 16
X + 4 otherwise
where X = (%laneid & 0b1) + (i & 0b10) for ci where i = {0,..,7}
col = (i & 0b100) + (%laneid & 0b10) + (i & 0b1) for ci where i = {0,..,7}9.7.14.5.2. Matrix Fragments for mma.m8n8k4 with .f64 floating point type
A warp executing mma.m8n8k4 with .f64 floating point type will compute an MMA operation of shape .m8n8k4.
Elements of the matrix are distributed across the threads in a warp so each thread of the warp holds a fragment of the matrix.
Multiplicand A:
The layout of the fragments held by different threads is shown in Figure 53.
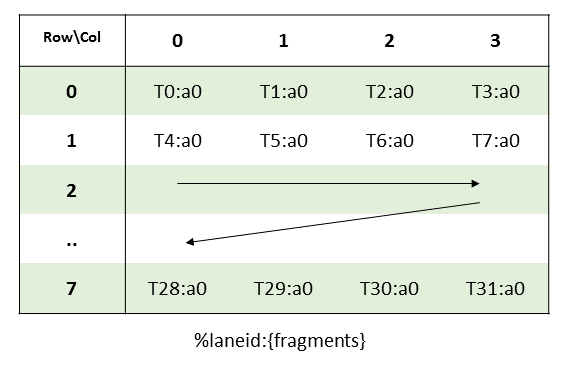
Figure 53 MMA .m8n8k4 fragment layout for matrix A with
.f64typeThe row and column of a matrix fragment can be computed as:
row = %laneid >> 2 col = %laneid % 4Multiplicand B:
The layout of the fragments held by different threads is shown in Figure 54.
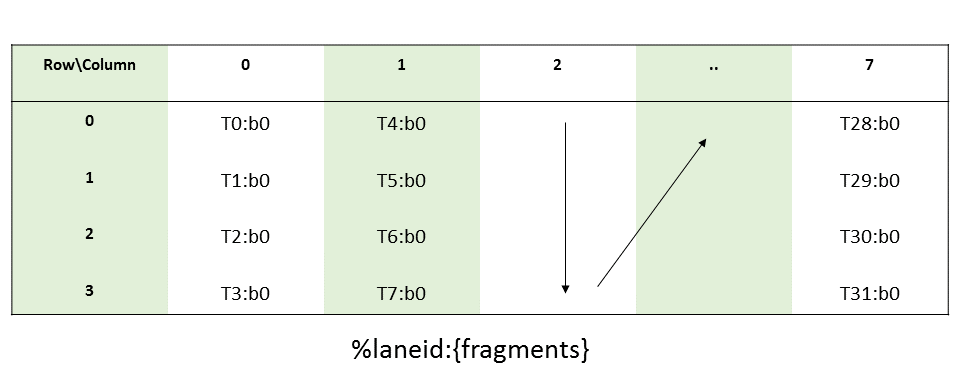
Figure 54 MMA .m8n8k4 fragment layout for matrix B with
.f64typeThe row and column of a matrix fragment can be computed as:
row = %laneid % 4 col = %laneid >> 2Accumulators (C or D):
The layout of the fragments held by different threads is shown in Figure 55.
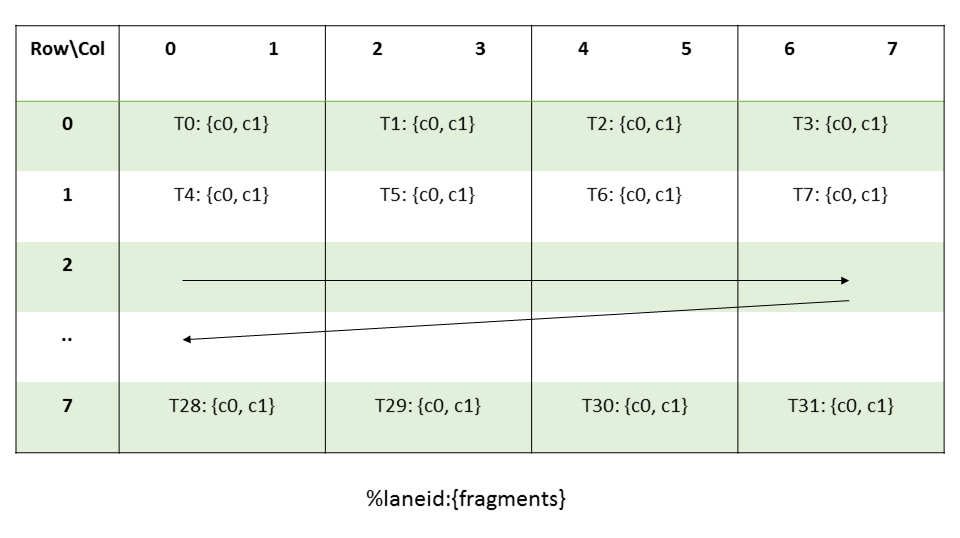
Figure 55 MMA .m8n8k4 fragment layout for accumulator matrix C/D with
.f64typeThe row and column of a matrix fragment can be computed as:
groupID = %laneid >> 2 threadID_in_group = %laneid % 4 row = groupID col = (threadID_in_group * 2) + (i & 0x1) for ci where i = {0, 1}
乘法累加指令:mma
执行矩阵乘法和累加运算
语法
半精度浮点类型
mma.sync.aligned.m8n8k4.alayout.blayout.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k8.row.col.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k16.row.col.dtype.f16.f16.ctype d, a, b, c;
.alayout = {.row, .col};
.blayout = {.row, .col};
.ctype = {.f16, .f32};
.dtype = {.f16, .f32};替代浮点类型
mma.sync.aligned.m16n8k4.row.col.f32.tf32.tf32.f32 d, a, b, c;
mma.sync.aligned.m16n8k8.row.col.f32.atype.btype.f32 d, a, b, c;
mma.sync.aligned.m16n8k16.row.col.f32.bf16.bf16.f32 d, a, b, c;
mma.sync.aligned.shape.row.col.dtype.f8type.f8type.ctype d, a, b, c;
mma.sync.aligned.m16n8k32.row.col.kind.dtype.f8f6f4type.f8f6f4type.ctype d, a, b, c;
.atype = {.bf16, .tf32};
.btype = {.bf16, .tf32};
.f8type = {.e4m3, .e5m2};
.f8f6f4type = {.e4m3, .e5m2, .e3m2, .e2m3, .e2m1};
.ctype = {.f16, .f32};
.dtype = {.f16, .f32};
.shape = {.m16n8k16, .m16n8k32};
.kind = {.kind::f8f6f4};带块缩放的替代浮点类型
mma.sync.aligned.m16n8k64.row.col.kind.block_scale{.scale_vec_size}.f32.e2m1.e2m1.f32.stype d, a, b, c, scale-a-data, {byte-id-a, thread-id-a}, scale-b-data, {byte-id-b, thread-id-b};
.kind = {.kind::mxf4};
.scale_vec_size = {.scale_vec::2X};
.stype = {.ue8m0};
mma.sync.aligned.m16n8k64.row.col.kind.block_scale.scale_vec_size.f32.e2m1.e2m1.f32.stype d, a, b, c, scale-a-data, {byte-id-a, thread-id-a}, scale-b-data, {byte-id-b, thread-id-b};
.kind = {.kind::mxf4nvf4};
.scale_vec_size = {.scale_vec::2X, .scale_vec::4X};
.stype = {.ue8m0, .ue4m3};
mma.sync.aligned.m16n8k32.row.col.kind.block_scale{.scale_vec_size}.f32.f8f6f4type.f8f6f4type.f32.stype d, a, b, c, scale-a-data, {byte-id-a, thread-id-a}, scale-b-data, {byte-id-b, thread-id-b};
.kind = {.kind::mxf8f6f4};
.scale_vec_size = {.scale_vec::1X};
.f8f6f4type = {.e4m3, .e5m2, .e3m2, .e2m3, .e2m1};
.stype = {.ue8m0};双精度浮点类型
mma.sync.aligned.shape.row.col.f64.f64.f64.f64 d, a, b, c;
.shape = {.m8n84, .m16n8k4, .m16n8k8, .m16n8k16};整型
mma.sync.aligned.shape.row.col{.satfinite}.s32.atype.btype.s32 d, a, b, c;
.shape = {.m8n8k16, .m16n8k16, .m16n8k32}
.atype = {.u8, .s8};
.btype = {.u8, .s8};
mma.sync.aligned.shape.row.col{.satfinite}.s32.atype.btype.s32 d, a, b, c;
.shape = {.m8n8k32, .m16n8k32, .m16n8k64}
.atype = {.u4, .s4};
.btype = {.u4, .s4};单bit类型
mma.sync.aligned.shape.row.col.s32.b1.b1.s32.bitOp.popc d, a, b, c;
.bitOp = {.xor, .and}
.shape = {.m8n8k128, .m16n8k128, .m16n8k256}