CUTLASS从入门到放弃系列(一) ------ 简介
简介
CUTLASS 4.2.0
CUTLASS 4.2.0 - Aug 2025
CUTALSS是一组抽象概念,用于在CUDA中实现高性能矩阵矩阵乘法(GEMM)和所有级别和规模的相关计算。它结合了分层分解和数据移动的策略。CUTLASS将这些“移动部件”分解为可重用的模块化软件组件和抽象。
概念并行化层次结构的不同级别的原语可以通过自定义平铺大小、数据类型和其他算法策略进行专门化和调整。由此产生的灵活性简化了它们在自定义内核和应用程序中作为构建块的使用。
CUTALSS自2017年以来一直为高性能线性代数提供CUDA C++模板抽象,这些抽象为广泛的计算提供了广泛的支持,包括混合精度计算、专用数据移动(异步复制)和FP64、FP32、TF32、FP16、BF16的乘法累加抽象,以及通过张量核心指令的FP32仿真、8b浮点类型(e5m2和e4m3)、块缩放数据类型(NVIDIA NVFP4和OCP标准MXFP4、MXFP6、MXFP8)、窄整数类型(4和8b有符号和无符号整数)和二进制1b数据类型(架构允许对这些数据类型的原生支持),这些数据类型跨越NVIDIA的Volta、Turing、Ampere、Ada、Hopper和Blackwell架构。
对于这个基于C++的内核编程抽象的丰富生态系统,CUTLASS 4添加了CUTLASS DSL。这些是Python原生接口,用于基于核心CUTALSS和CuTe概念编写高性能CUDA内核,而不会对性能产生任何影响。这允许更平滑的学习曲线,更快的编译时间,与DL框架的原生集成,而无需编写粘合代码,以及更直观的元编程,不需要深厚的C++专业知识。
总体而言,我们将CUTLASS DSL视为一个领域特定语言(DSL)。随着4.0的发布,我们将在CuTe DSL中发布其中的第一个版本。这是一个低级编程模型,与CuTe C++抽象完全一致,暴露了布局、张量、硬件原子等核心概念,以及对硬件线程和数据层次结构的完全控制。
CuTe DSL演示了针对NVIDIA的Ampere、Hopper和Blackwell架构实现的可编程、高吞吐量tensor core的最优矩阵乘法和其他线性代数运算。
我们相信,它将成为学生、研究人员和性能工程师不可或缺的工具——使GPU编程的学习曲线变得平坦,快速原型化内核设计,并将优化的解决方案投入生产。
CuTe DSL目前处于公开测试阶段,将于2025年夏末从测试阶段毕业。
CUTLASS 4.2中的新特性
CuTe DSL
我们可能会跳过4.2.dev版本,直接发布4.2。
在此之前,CuTeDSL版本仍为4.1.0。
CUTLASS C++
为Hopper SM90分块内核添加以K主的scale因子支持。
在示例77中展示的进一步增强的Blackwell SM100 Attention内核。
为cutlass MLA添加融合内核支持。
修复get_unmasked_trip_count可能返回负值的问题。
修复mbarriers初始化为零到达计数的问题。
加Blackwell SM120分块gemm内核示例:示例87。
支持Blackwell SM100异步内核。
集体主循环代码:cpasync主循环。
内核代码:cpasync内核。
Support for Blackwell SM121 kernels for DGX Spark GPUs.
Share the major codes with Blackwell SM120 kernels.
Support for Blackwell SM100 legacy mixed input GEMM kernels.
Collective mainloop codes: Mixed input mainloop.
Kernel codes: Mixed input kernel.
Example codes: example 86.
Support for Blackwell SM100 fp4 gemv kernels.
Kernel codes: Gemv kernel.
Example codes: example 91
From CUDA 13.0, the Blackwell SM101 for Thor GPUs is renamed to SM110.
For CUDA toolkit version < 13.0, SM101 is still used for Thor GPUs.
For CUDA toolkit version >= 13.0, SM110 is used for Thor GPUs and SM101 is no longer valid.
CuTe changes:
Fix inaccurate GridDim calculation under CuTe tutorial.
Add movmatrix support.
Fix smallest MMA-N allowed for Blackwell fp8 and fp16 gemm kernels.
Support fp16 accmulator for sm89 fp8 mma.
Shorten
nullspaceimplementation.Isolate and comment on
cosizehacks.Important documentation correction:
E<0,1> == 1@0@1.
Add support for heuristics-based kernel filtering and autotuning using
nvidia-matmul-heuristics.Details please refer to heuristics doc.
Rename legacy Python API package from
cutlasstocutlass_cppgen.Fix some profiler issues:
Modify default cluster callback values to none 0 to avoid profiler failure when these values are not set in command line.
Fix some no output and timeout issues.
Add following unit tests:
有关所有过去版本和更新的详细信息,请参阅CHANGELOG。
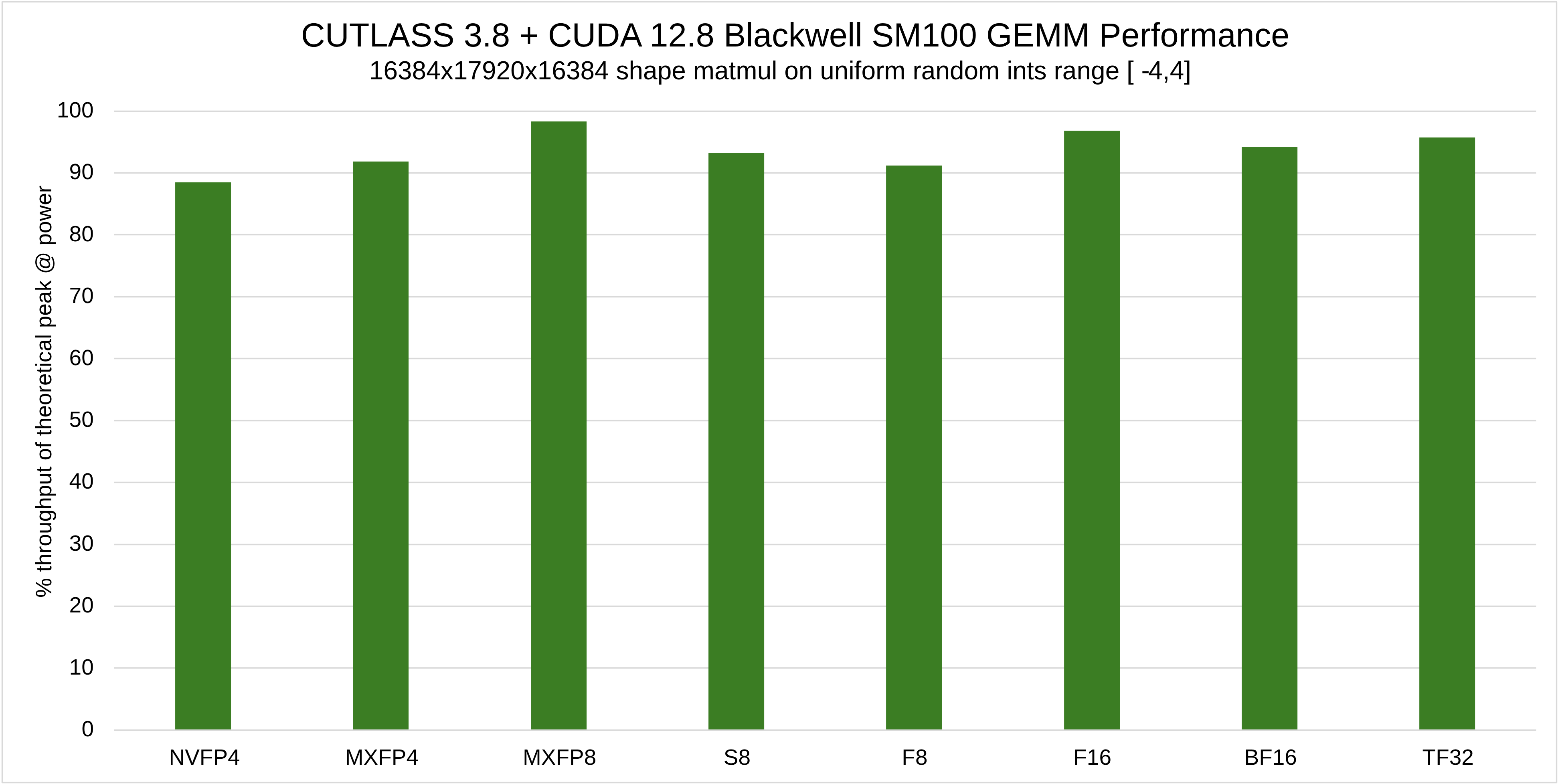
CUTLASS原语非常高效。当用于构建设备范围的GEMM内核时,它们表现出了接近峰值理论吞吐量的最优利用率。下图显示了CUTLASS 3.8在NVIDIA Blackwell SM100架构GPU上运行时,在各种输入和输出数据类型上的性能占理论峰值利用率的百分比。
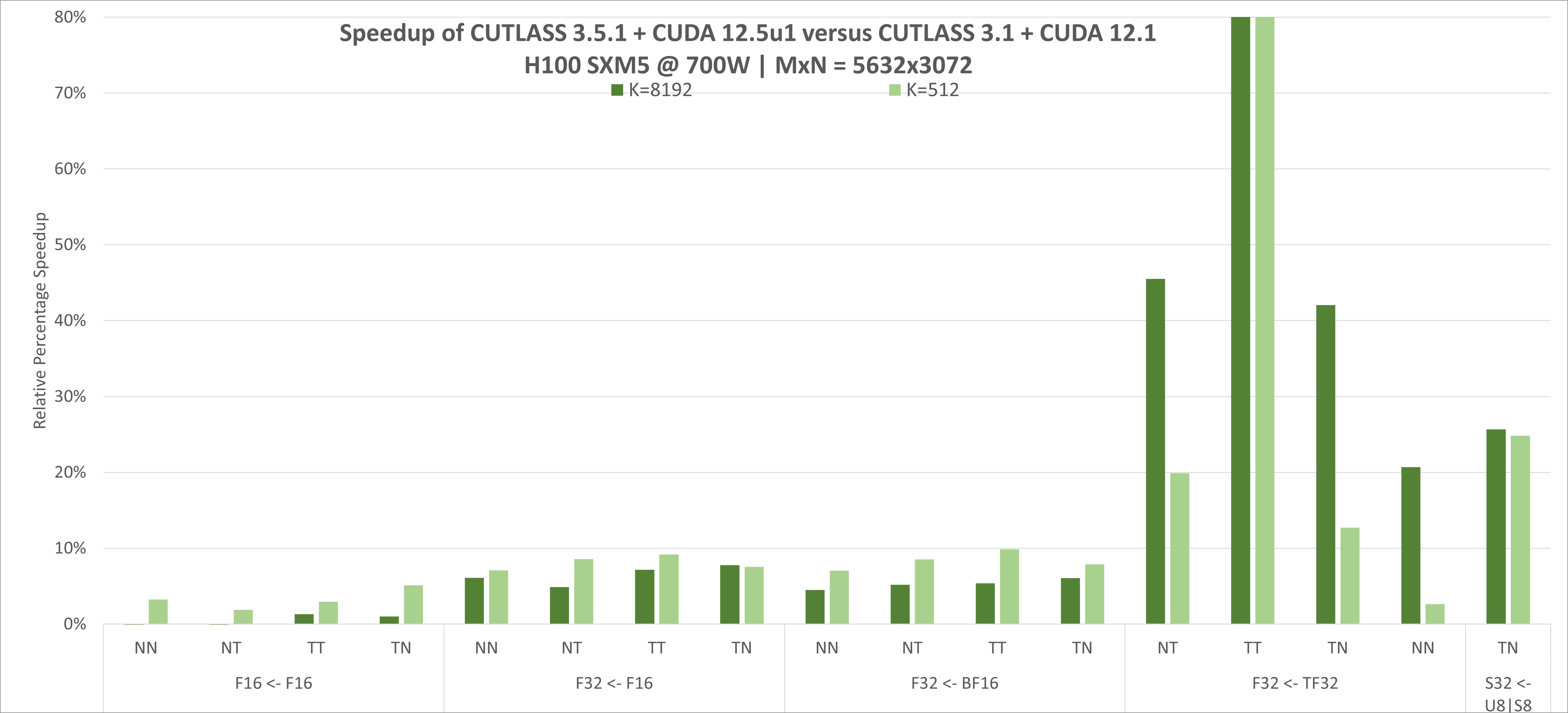
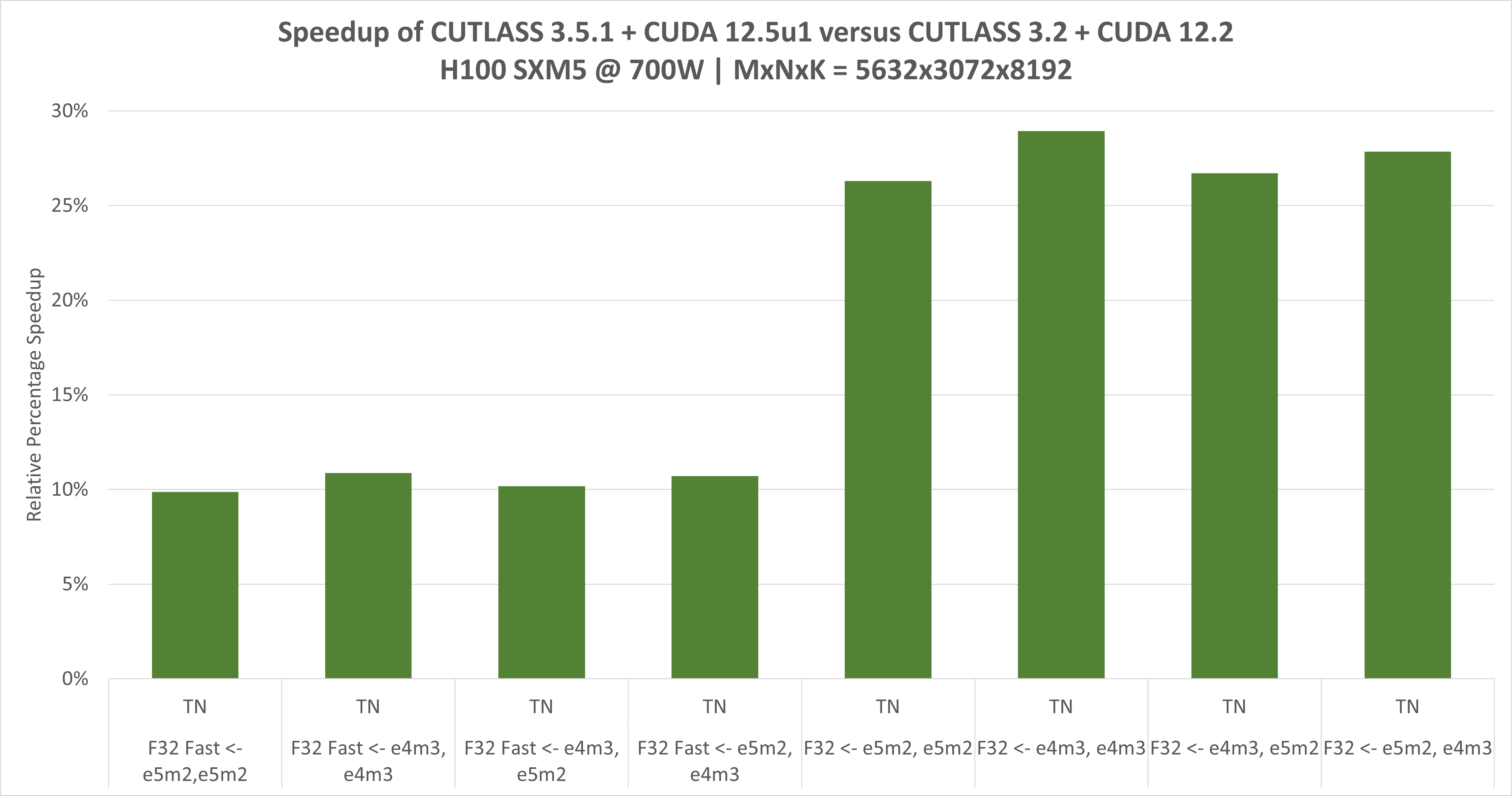
下图显示了自CUTLASS 3.1以来,NVIDIA H100(NVIDIA Hopper架构)的CUTLASS性能持续改进。CUTALSS 3.5.1是用CUDA 12.5u1工具包编译的。Tensor Core操作是使用CUDA的mma和wgmma指令实现的。
CuTe
CUTALSS 3.0引入了一个新的核心库CuTe,用于描述和操作线程和数据的张量。CuTe是C++CUDA模板抽象的集合,用于定义和操作线程和数据的分层多维布局。CuTe提供Layout和Tensor对象,它们紧凑地打包数据的类型、形状、存储空间和布局,同时为用户执行复杂的索引。这让程序员专注于他们算法的逻辑描述,而CuTe则为他们做机械转换等工作。有了这些工具,我们可以快速设计、实现和修改所有稠密的线性代数运算。
CuTe的核心抽象是分层多维布局,可以用数据数组来表示张量。布局的表示足够强大,几乎可以表示实现高效稠密线性代数所需的一切。布局也可以通过函数组合进行组合和操纵,我们在其上构建了一系列常见的操作,如平铺和分区。
CUTLASS 3.0及更高版本在其模板中的整个GEMM层次结构中采用了CuTe。这大大简化了设计,提高了代码的可组合性和可读性。可以在CuTe的专用文档目录中找到更多特定于CuTe的文档。
兼容性
最低要求:
架构:Volta(计算能力7.0)
编译器:必须至少支持C++17
CUDA工具包版本:11.4
CUTALSS需要一个C++17 host编译器,使用CUDA 12.8 Toolkit构建时性能最佳。它还与CUDA 11.4、CUDA 11.5、CUDA 11.6、CUDA 11.7、CUDA11.8和所有其他CUDA 12.x版本兼容。