TensorRT 中的量化
1. 量化入门
TensorRT通过支持量化来实现高性能推理,量化是一种通过用较低精度的数据类型表示浮点值来减少模型大小并加速计算的技术。除了原始性能之外,量化对于减少内存占用和提高能源效率至关重要,使其非常适合部署在资源受限的边缘设备上,并在大规模数据中心部署中实现更高的成本效益。
TensorRT采用对称量化方案,其中激活和权重都映射到以零为中心的量化值。这种方法简化了量化和浮点表示之间的转换,通常只涉及缩放因子。TensorRT中支持的量化数据类型包括:
INT8(带符号的8位整数)
INT4(带符号的4位整数,仅权重量化)
FP8E4M3(FP8,8位浮点,4个指数和3个尾数位)
FP4E2M1(FP4,4位浮点,2个指数和1个尾数位)
这些低精度格式使TensorRT能够在保持准确性的同时提供高效的推理,使其适用于资源受限的环境和高吞吐量应用程序的部署
1.1 量化工作流程
TensorRT支持训练后量化(PTQ)和量化感知训练(QAT)工作流程,使用户能够针对低精度数据类型优化模型。量化过程根据层和数据类型使用每个张量、每个通道或逐块缩放,以在转换过程中最好地保持模型精度
PTQ涉及量化预先训练的模型,而无需重新训练。这种方法需要使用代表性的“校准数据”集运行模型,以计算离线激活的量化参数。当由于资源限制或数据隐私问题而无法进行再培训时,PTQ非常实用。然而,值得注意的是,PTQ可能会导致精度下降,特别是对于复杂的模型或敏感层。
QAT通过量化权重和激活层来模拟训练过程中的量化。这使得训练过程能够主动补偿量化和去量化操作的影响,与PTQ相比,通常可以实现更高的精度恢复。虽然QAT可以在较低的精度下实现高精度,但它更耗时,需要访问整个(标记的)训练数据集,并需要更多的计算资源。
TensorRT模型优化器是一个Python工具包,旨在促进创建与TensorRT的优化和部署工作流程完全兼容的量化感知训练(QAT)模型。此外,该工具包提供了一个训练后量化(PTQ)配方,使用户能够对以PyTorch和ONNX格式开发的模型执行PTQ,简化了不同框架之间的量化过程。
1.2 显式量化与隐式量化
隐式量化已被弃用。强烈建议用户过渡到显式量化,通常是通过使用TensorRT模型优化器创建具有显式量化的模型。
量化网络可以通过两种(互斥)方式进行处理:使用隐式或显式量化。这两种处理模式之间的主要区别在于,你是需要对量化进行显式控制,还是让TensorRT构建器选择要量化的操作和张量(隐式)。以下部分提供了更多详细信息。仅当对INT8进行量化时才支持隐式量化。它只能与弱类型一起使用,弱类型也被弃用。
当网络具有QuantizeLayer和DequantizeLayer层(简称Q/DQ)时,TensorRT使用显式量化模式。它被称为显式量化,因为Q/DQ层用于控制网络中的量化和解量化。当网络中没有QuantizeLayer或DequantizeLayer层,并且在构建器配置中启用了INT8和弱类型时,TensorRT使用隐式量化模式。隐式量化模式仅支持INT8。
在隐式量化网络中,具有由校准过程分配的或由API函数setDynamicRange分配的相关标度的每个激活张量被考虑用于量化。
在处理隐式量化网络时,TensorRT在应用图优化时将模型视为浮点模型,并机会主义地使用INT8来优化层执行时间。如果一个层在INT8中运行得更快,并且在其数据输入和输出上分配了量化尺度,则将具有INT8精度的内核分配给该层。否则,将分配高精度浮点(FP32、FP16或BF16)内核。隐式量化已被弃用,不鼓励使用。
在显式量化网络中,量化和去量化操作由图中的IQuantizeLayer(C++,Python)和IDequantizeLayer(C++,Python)节点显式表示,这些节点此后将被称为Q/DQ节点。与隐式量化相比,显式形式精确地指定了执行量化类型转换的位置,优化器将仅执行由模型语义决定的量化类型转换。
ONNX使用显式量化表示:当PyTorch或TensorFlow中的模型导出到ONNX时,框架图中的每个伪量化操作都会导出为Q,然后是DQ。由于TensorRT保留了这些层的语义,用户可以期望非常接近深度学习框架中的精度。虽然优化保留了量化和去量化运算符的算术语义,但它们可能会改变模型中浮点运算的顺序,因此结果不会逐位相同。
显式量化具有显著的优势,如下表所示:
更广泛的数据类型支持:它支持更广泛的量化数据类型,包括INT8、FP8、INT4和FP4。
直接用户控制:Q/DQ节点提供对量化类型转换执行位置的精确控制。
维护模型语义:确保优化器只执行由模型固有语义决定的转换,从而获得非常接近原始框架中观察到的准确性。
与ONNX导出的兼容性:在深度学习框架中执行QAT或PTQ,然后导出到ONNX,自然会得到一个明确量化的模型,因为ONNX将伪量化操作表示为Q/DQ对。
隐式量化和弱类型有着内在的联系。隐式量化是一种机会主义方法,其中TensorRT构建器自动确定要量化哪些操作和张量,这需要在构建器配置中使用弱类型。弱类型允许TensorRT对精度做出灵活的即时决策,因为INT8的类型转换完全依赖于构建器的内部启发式,而不是显式的QuantizeLayer和DequantizeLayer层。然而,隐式量化和弱类型现在都被弃用了,因为与显式量化工作流程相比,它们提供的控制更少,数据类型支持更窄。
开发人员必须了解,对于具有Q/DQ节点的模型,不应提供外部校准表,因为如果模型中已经存在Q/DQ节点,TensorRT不允许加载校准表。这意味着,对于显式模型,在ONNX导出之前(例如,在使用模型优化器进行PTQ/QAT期间)进行校准,并将得到的比例直接嵌入Q/DQ节点中。
虽然显式量化是推荐的面向未来的方法,但值得注意的是,对于某些网络,与隐式量化相比,初始显式量化可能会表现出更高的延迟。然而,模型优化器团队正在积极与TensorRT团队合作,以尽量减少各种模型之间的差距。
1.3 量化粒度
量化粒度是指量化比例因子如何应用于模型的张量。选择适当的粒度是平衡量化的好处(如内存减少)与其潜在缺点(精度损失)的直接手段。方法越精细,潜在的精度就越高,但与管理多个缩放因子相关的计算和内存开销也就越高。TensorRT中支持三种量化尺度粒度:
每张量量化:使用单个缩放值(标量)来缩放整个张量。
每通道量化:沿给定轴广播一个尺度张量——对于卷积神经网络,这通常是通道轴。
块量化:张量沿一维被划分为固定大小的一维块。为每个块定义一个比例因子
当使用卷积的每通道量化时,量化轴必须是输出通道轴。例如,当使用KCRS表示法描述2D卷积的权重时,K是输出信道轴,权重量化可以描述为:
For each k in K:
For each c in C:
For each r in R:
For each s in S:
output[k,c,r,s] := clamp(round(input[k,c,r,s] / scale[k]))尺度是系数的向量,必须与量化轴具有相同的大小。
除了定义为以下的逐点操作外,反量化的执行方式类似:
output[k,c,r,s] := input[k,c,r,s] * scale[k]块量化
在块量化中,元素被分组为1D块,块中的所有元素共享一个共同的比例因子。块量化支持高达3维的输入。
INT4块量化支持仅权重量化(WoQ)。
FP4块量化支持权重和激活。为了尽量减少量化误差,建议对激活使用动态量化。
当使用块量化时,除了执行块化的一个维度(块轴)外,尺度张量维度等于数据张量维度。例如,给定一个2-D RS权重输入,R(维度0)作为块轴,B作为块大小,块轴中的比例根据块大小重复,可以这样描述:
For each r in R:
For each s in S:
output[r,s] = clamp(round(input[r,s] / scale[r//B, s]))该尺度是一个二维系数数组,其维度为(R//B,S)。
除逐点操作定义为:
output[r,s] = input[r,s] * scale[r//B, s]1.4 量化类型舍入模式
TensorRT主要采用舍入到最近偶数的方法(也称为“银行家舍入”),在平局的情况下舍入到最近的偶数值(例如,2.5轮到2,3.5轮到4)。这种方法有助于减少量化过程中的系统偏差,防止其他舍入策略可能出现的持续向上或向下漂移。
后端:GPU计算内核量化(FP32到INT8/FP8):
四舍五入到最接近偶数权重量化(FP32到INT8/FP8/INT4/FP4)
显式量化:四舍五入到与偶数(INT8、FP8、INT4、FP4)相关的最近值
隐式量化:四舍五入到最近值,与正无穷大相关(仅INT8)
后端:DLA计算内核量化(FP32到INT8/FP8):
四舍五入到最接近偶数权重量化(FP32到INT8/FP8/INT4/FP4)
显式量化:N/A
隐式量化:四舍五入到最近值,与偶数(仅INT8)挂钩
有关舍入模式的更多信息,请参阅舍入
1.5 动态量化
动态量化是一种量化形式,其中在推理过程中根据输入数据计算尺度。它产生两个输出:量化数据和缩放。TensorRT仅支持块量化粒度的动态量化。
动态量化有两个主要好处:
精度:通过动态量化,选择一个比例,将单个块的动态范围映射到量化类型。由于单个块的动态范围通常比整个张量的动态范围小得多,因此量化误差减小了。这对于半字节量化类型最为重要,因为这些数据类型中可表示的值范围很小。
减少PTQ开销:由于在推理过程中自动计算标尺,因此用户不需要根据样本数据校准标尺。
对于每个块,比例计算如下:
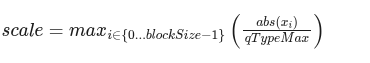
其中qTypeMax是量化类型中的最大值(例如FP4E2M1为6)。
1.5.1 符合MX标准的动态量化
根据OCP微尺度格式(MX)规范v1.0进行动态量化。MX编译器配方执行块量化,在32个高精度元素上进行量化,以产生32个量化输出值和一个E8M0缩放因子。
TensorRT目前仅支持FP8E4M3矢量格式(称为MXFP8)的MX兼容动态量化。
单个块的sacle计算定义为:
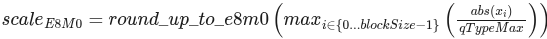
E8M0是一种仅支持8位指数的浮点类型,如“支持的类型”中所述。
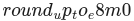 是向大于或等于它的2的最小幂四舍五入的计算比例。
是向大于或等于它的2的最小幂四舍五入的计算比例。qTypeMax是用于量化的数据类型中可表示的最大值。
对每个块重复进行规模计算,计算出总共
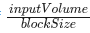 个块sacle
个块sacle
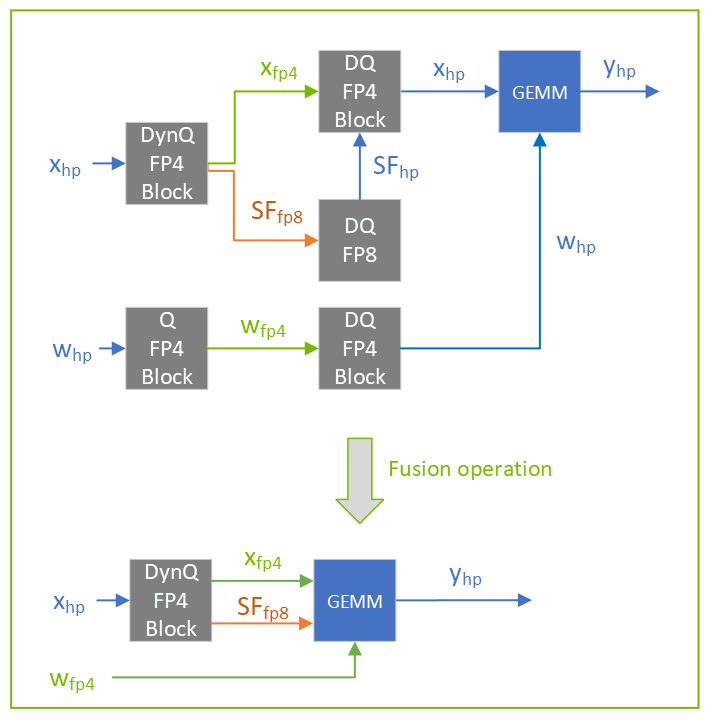
1.5.2 动态双量化
动态量化的一种变体,其中计算的尺度也被量化。将单个块的缩放计算和缩放量化放在一起

其中globalSf是一个离线校准的每个张量量化尺度(标量)。
TensorRT目前仅支持NVFP4矢量格式的动态双量化(FP4E2M1数据,FP8E4M3缩放,块大小为16)。
使用qTypeMax=6,和FP8范围为[-448448],量化尺度可写为:
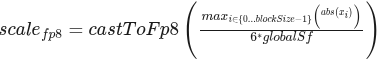
使用块量化和计算的尺度来计算量化数据。
为了对使用动态双量化量化的数据进行去量化,必须进行两次连续的去量化操作(因此称为双量化):第一次使用每张量量化对尺度进行去量化;第二次使用数据去量化。
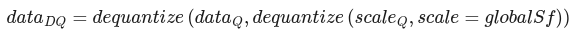
2.量化方案
3. 显式量化
当TensorRT检测到网络中存在Q/DQ层时,它会使用显式量化处理逻辑构建一个引擎。本节的其余部分将更详细地描述显式量化是如何工作的。
显式量化可以与强类型或弱类型一起使用(不需要也不应指定精度控制构建标志),但由于弱类型已被弃用,建议用户始终使用强类型。
3.1 量化权重
Q/DQ模型的权重可以使用高精度数据类型(FP32、FP16或BF16)或低精度量化类型(INT8、FP8、INT4、FP4)指定。当TensorRT构建引擎时,使用IQuantizeLayer标尺对高精度权重进行量化,该标尺对权重进行操作。量化(低精度)权重存储在发动机计划文件中。当使用预量化权重时,在权重和使用权重的线性算子之间需要一个IDequantizeLayer。
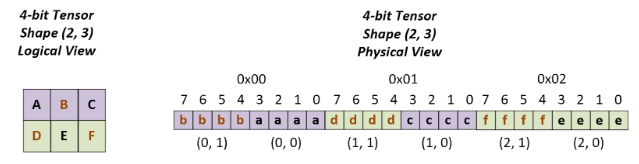
INT4和FP4量化权重通过每字节打包两个元素来存储。如下图所示,第一个元素存储在4个最低有效位中,第二个元素存储于4个最高有效位中。
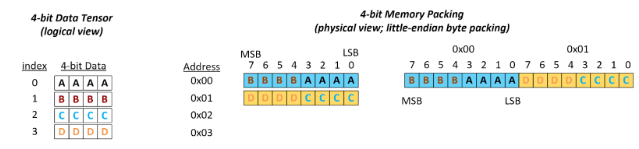 下图显示了打包(2,3)4位张量的示例。
下图显示了打包(2,3)4位张量的示例。
 3.2 ONNX支持
3.2 ONNX支持
当使用量化感知训练(QAT)在PyTorch或TensorFlow中训练的模型导出到ONNX时,框架图中的每个伪量化操作都会导出为一对QuantizeLinear和DequantizeLinear ONNX运算符。当TensorRT导入ONNX模型时,ONNX QuantizeLinear操作符作为IQuantizeLayer实例导入,ONNX DequantizeLinear运算符作为IDequantizeLayer实例引入。
ONNX在opset 10中引入了对QuantizeLinear和DequantizeLinear的支持,并在opset 13中添加了量化轴属性(每信道量化所需)。PyTorch 1.8引入了使用opset 13将PyTorch模型导出到ONNX的支持。
ONNX opset 19增加了四种FP8格式,其中TensorRT支持E4M3FN(在ONNX运算符模式中也称为张量(float8e4m3fn))。最新的Pytorch版本(Pytorch 2.0)不支持FP8格式,也不支持使用opset 19导出到ONNX。为了弥合这一差距,TransformerEngine将其FP量化函数导出为属于“trt”域的自定义ONNX Q/DQ运算符(trt_FP8 QuantizeLinear和trt_FP8-DequantizeLinear)。TensorRT可以解析自定义运算符和标准opset 19 Q/DQ运算符;然而,值得注意的是,TensorRT并不完全支持opset 19。ONNX Runtime等其他工具无法解析自定义运算符。ONNX opset 21增加了对INT4数据类型和块量化的支持。ONNX opset 23增加了对FP4E2M1类型的支持。
因此,TensorRT会转置pyTorch权重。TensorRT在权重转置之前对其进行量化,因此源自PyTorch导出的ONNX QAT模型的GEMM层使用维度0进行每通道量化(轴K=0),而源自TensorFlow的模型使用维度1(轴K=1)。
TensorRT不支持使用INT8/FP8量化运算符的预量化ONNX模型。具体来说,不支持以下ONNX量化运算符,如果TensorRT导入ONNX模型时遇到这些运算符,则会生成导入错误:
3.3 Q/DQ网络的TensorRT处理
当TensorRT在Q/DQ模式下优化网络时,优化过程仅限于不改变网络算术正确性的优化。由于浮点运算的顺序可能会产生不同的结果(例如,重写a*s + b*s作为(a+b)*s是有效的优化)。允许这些差异通常是后端优化的基础,这也适用于将具有Q/DQ层的图转换为使用量化操作。
Q/DQ层控制网络的计算和数据精度。IQuantizeLayer实例通过量化将高精度浮点张量转换为量化张量,IDequantizeLayer实例使用逆量化将量化张量转换为高精度浮点tensor。TensorRT期望在可量化层的每个输入上都有一个Q/DQ层对。可量化层是深度学习层,可以通过与IQuantizeLayer和IDequantizeLayer实例融合转换为量化层。当TensorRT执行这些融合时,它会用量化层替换可量化层,这些量化层使用适用于量化类型的计算操作对量化数据进行操作
对于本章中使用的图表,绿色表示低精度(量化),蓝色表示高精度。箭头表示网络激活张量,正方形表示网络层。
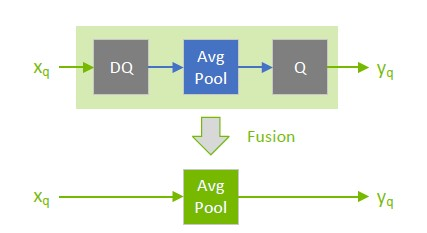 在网络优化过程中,TensorRT在Q/DQ传播中移动Q/DQ层。传播的目标是最大化可以低精度处理的图的比例。因此,TensorRT向后传播Q节点(量化尽可能早),向前传播DQ节点(去量化尽可能晚)。Q层可以与量化转换的层交换位置,DQ层可以与去量化转换的图层交换位置。
在网络优化过程中,TensorRT在Q/DQ传播中移动Q/DQ层。传播的目标是最大化可以低精度处理的图的比例。因此,TensorRT向后传播Q节点(量化尽可能早),向前传播DQ节点(去量化尽可能晚)。Q层可以与量化转换的层交换位置,DQ层可以与去量化转换的图层交换位置。
一个层op如果满足以下条件,则与量化进行交换
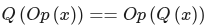
同样,一个层op如果满足以下条件,则通过逆量化进行交换
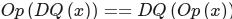 下图说明了DQ正向传播和Q反向传播。这些是对模型的合法重写,因为Max Pooling具有INT8实现,并与DQ和Q进行交换。
下图说明了DQ正向传播和Q反向传播。这些是对模型的合法重写,因为Max Pooling具有INT8实现,并与DQ和Q进行交换。