CuTe DSL介绍
概览 CUTALSS 4.x弥合了CUDA内核开发的生产力和性能之间的差距。通过为功能强大的CUTALSS C++模板库提供基于Python的DSL,它可以在NVIDIA GPU上实现更快的迭代、更容易的原型制作和更平缓的高性能线性代数学习曲线。 总体而言,我们将CUTLASS DSL视为一个领域特
cutlass cuda c++实现快速线性代数
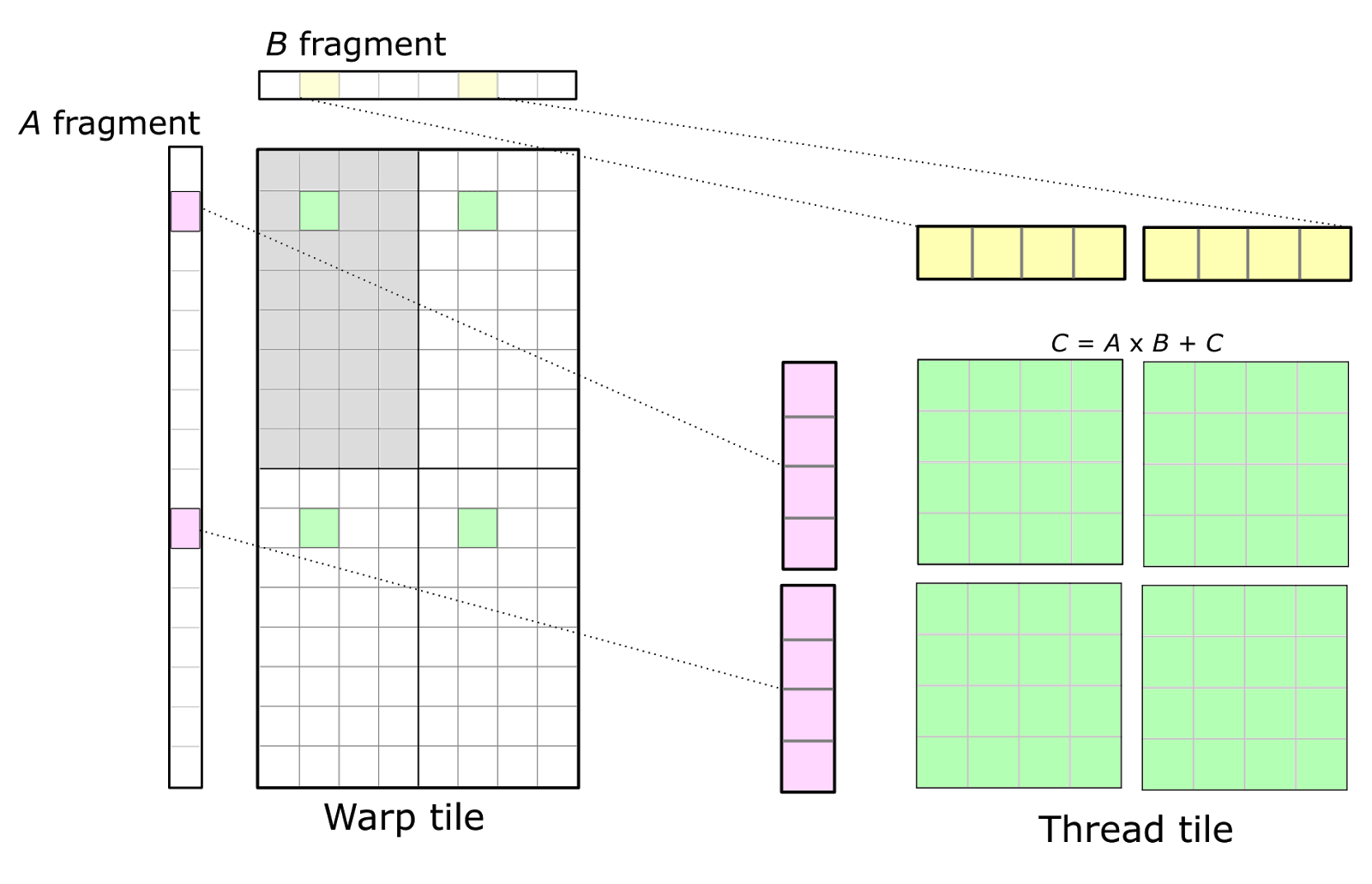
矩阵乘法是许多科学应用中的核心计算,特别是在深度学习中。现代深度神经网络中的许多操作要么被定义为矩阵乘法,要么可以被转换为矩阵乘法。 例如,NVIDIA cuDNN库使用各种形式的矩阵乘法实现了神经网络的卷积,例如直接卷积的经典公式,即图像到列和滤波器数据集之间的矩阵乘积。当基于快速傅里叶变换(FF

gpu硬件架构
1.简介 NVIDIA在视觉计算和人工智能(AI)领域处于领先地位;其旗舰GPU已成为解决包括高性能计算和人工智能在内的各个领域复杂计算挑战所不可或缺的产品。虽然它们的规格经常被讨论,但很难掌握各种组件的清晰完整的图景。 这些GPU的高性能源于其许多组件的无缝集成,每个组件在提供顶级结果方面都发挥着